Ling/CSE 472: Assignment 2:
Finite State Transducers for Morphology and Phonology
Overview
In this assignment, you will create a morphologiacal analyzer for
the fictional language Kaixo. This entails:
- Getting access to the software, either by using it on patas or installing it locally
- Reading a description of the language
- Handling the morphotactics of the language (the order in which morphemes occur)
- Handling the morphophonology of the language (the surface realization of different morphemes, depending on their morphological or phonological environment)
- Doing iterative development: starting with a small subset of the grammar and building out from there
- Writing up your results and reflections
Software: foma FST compiler. Installation and Tutorial.
This assignment involves using a FSA/FST tool foma.
- You can use foma on patas by typing this in the terminal:
/nopt/foma/bin/foma
- Alternatively if your machine runs OSX or a Linux, install foma by downloading the appropriate precompiled binaries from
here
and copying the file called "foma" into your /usr/local/bin directory.
- After that, check that you can type "foma" in the terminal and you should see "foma[0]:",
waiting for your input.
- Mans Hulden's tutorial explains the functionality we'll be using.
- We recommend coming back to the section on FLAGS when you use those in the later part of the assignemnt.
- Try the various commands in the tutorial at the foma prompt on your machine (or patas). If you aren't seeing the expected behavior or have other questions, please post to Canvas!
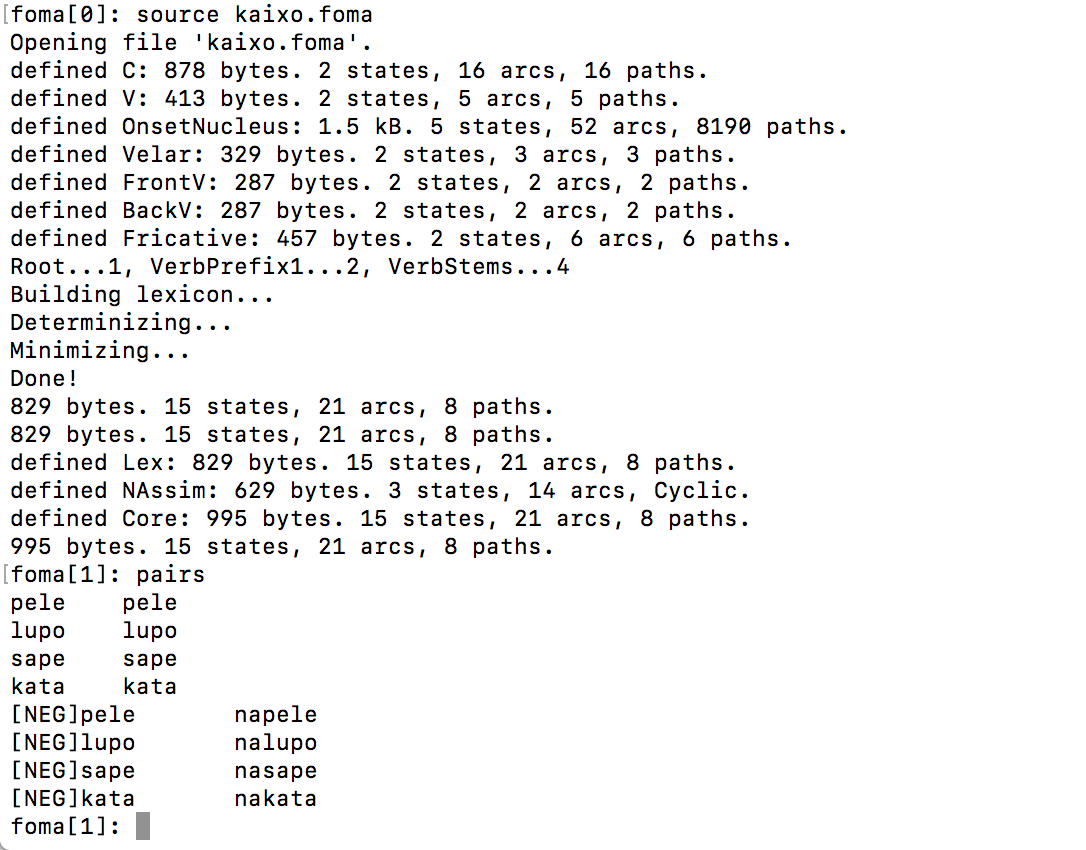
Note: when you download the skeleton files linked in the assignment description below and run the tool,
you should see this:
A grammar of Kaixo verbs
Kaixo is a fictitious language featuring a variety of morphological and phonological phenomena.
You will approach this assignment as a true computational linguist, starting
with a linguistic description of a language, mapping that description to a formalism (in this case, an FSA formalism foma),
and then implementing your hypotheses about the language in this formalism and testing them.
Follow this link for Kaixo description.
Start with what seems simple, e.g. just one affix and one
stem. Add things one by one and test as you go. Leave
what is less clear to you for later, don't get hung up for too
long. Ask questions.
Your tasks:
- Get the kaixo.lexc and kaixo.foma starter files.
- Test the grammar as given in these files:
- Load your grammar in foma (start foma first, you will see foma[0]:): source kaixo.foma
- Type: pairs (you will type this after foma[1]: in the terminal). You will see what your
automaton can generate.
- NB: pairs only displays the first 100 results. Once you add several phenomena, start dumping the output into a file (pairs > filename.txt ), to see full output.
- Build out the foma-style (FST) lexicon, kaixo.lexc, to represent the language's morphotactics (restrictions on the order and the cooccurrence of morphemes) for the following morpheme types:
- person and number
- negation
- durative aspect
- past and present tense
- Test your grammar:
- Do 3P and 1/2P occur in the same slot (position class)? Can you have two person markers in a word at the same time?
- For now, go with some solution for person, perhaps not an ideal one. You will have a chance to improve it later.
- Build out the foma-style FST kaixo.foma to handle some of the morphopnonology in the language, specifically:
- vowel harmony
- fricative breakup
- Test your grammar:
- Do the phonological rules have the intended effect?
- Reread the tutorial section on flags and the flag syntax exmaple in "hints" below
- Use flags to make it so:
- Either 3P or 1P/2P marker always appears but never both
- You don't have duplicate states for any morpheme.
- Bonus: Copy kaixo.lexc and kaixo.foma to new files called kaixo-bonus.lexc and kaixo-bonus.foma. Extend those files to handle:
- iterative
- evidentiality (hearsay)
Hints:
- For each of the markers, think: Is this affix obligatory or optional?
- For the person markers:
- Do you have both the 3P marker and the 1P/2P marker in your strings? This is not good.
- If you don't have strings containing more than one person marker, look at your kaixo.lexc file. Did you have to create more than one FSA state for the same morpheme (e.g. stems)?
- Do you have other ungrammatical strings generated (e.g. string without any person marker)?
- Make notes about the above for the write up. Discuss the pros and cons of the solution that you have. How does your solution relate to your linguistic hypotheses about the language?
- Flag example, in foma syntax (using arbitrary names for flags, inputs, and states):
- @U.FLAG.ON@:@U.FLAG.ON@character State1 ;
- basically means: if the input is "character", consider the FLAG turned on and transition to State1
- @U.FLAG.OFF@ State1 ;
- basically means: can transition to State1 for free (do not consume input) but in this case the FLAG can only be off.
- (Don't forget to add your flag names to Multichar_Symbols at the top of your kaxio.lexc)
Submit:
- On patas, create a directory named with your UWNetID inside dropbox/22-23/472/hw2 and copy these files there:
- kaixo.lexc
- kaixo.foma
- (bonus) kaixo-bonus.lexc
- (bonus) kaixo-bonus.foma
- In Canvas, submit your write up:
- A discussion of the person marker solution(s) which do not use flags. Pros and cons. Relation to linguistic hypotheses.
- What does it mean to use flags? Is your grammar still regular if you use them?
- Optional: If you have graphviz installed on your computer, type view in foma and inspect your automata. What does the engine do with your flags?
- Why are evidentiality and iterative aspect in Kaixo not easy to model using FST?
- Generally, what you learned about:
- morphology and phonology
- FST and regular languages
- anything else.
Last modified:
Back to main course page