These instructions might get edited a bit over the next couple of days. I'll try to flag changes.
As usual, check the write up instructions first.
Requirements for this assignment
Before making any changes to your grammar for this lab, run a baseline test suite instance. If you decide to add items to your test suite for the material covered here, consider doing so before modifying your grammar so that your baseline can include those examples. (Alternatively, if you add examples in the course of working on your grammar and want to make the snapshot later, you can do so using the grammar you turned in for Lab 4.)
The Matrix distinguishes scopal from intersective modification. We're going to pretend that everything is intersective and just not worry about the scopal guys for now (aside from negative adverbs, if you got one from the customization system).
head-adj-int := head-adj-int-phrase. adj-head-int := adj-head-int-phrase.
+nvcdmo :+ [ MOD < > ].
That adds the constraint [MOD < > ] to the type +nvcdmo, which is the supertype of all the head types other than adj and adv. (Notes: You might already have this constraint or a functionally equivalent one if your customized grammar includes adverbial negation, or from the adjectives library. Constraining +nvcdmo isn't necessarily the best way to do this, as you might want to allow nouny or verby things to be modifiers. The alternative is to constrain the relevant lexeme types to have empty MOD values.)
adverb-lex := basic-adverb-lex & intersective-mod-lex & [ SYNSEM [ LOCAL [ CAT [ HEAD.MOD < [ LOCAL.CAT.HEAD verb ]>, VAL [ SPR < >, SUBJ < >, COMPS < >, SPEC < > ]]]]].
The modifiers you are adding should share their LBL with the verb/noun they modify and take the ARG0 of the modifiee as their ARG1. Here are some examples that should what this looks like. (This is the "simple MRS" view.)
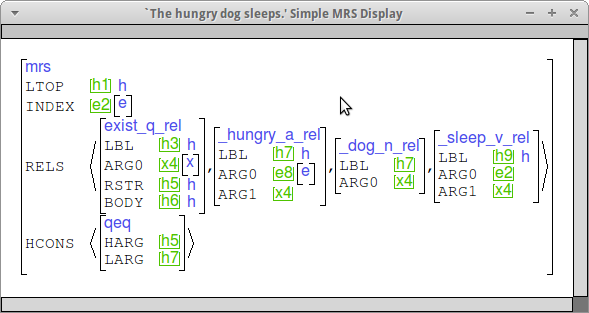
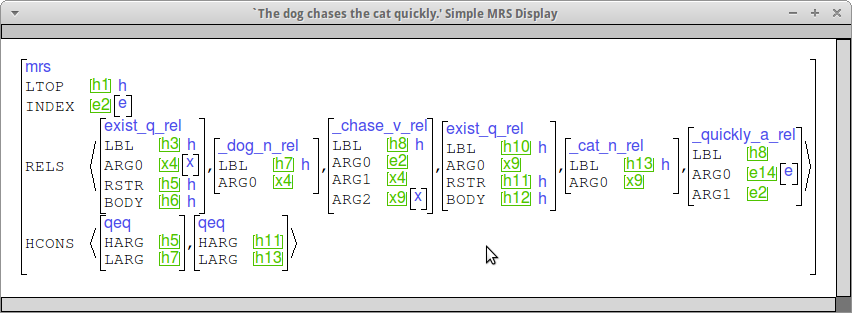
Adjective agreement lexical rules should be working from the work
you did in the customization system in Lab 4. In case they aren't,
below is some general information on writing lexical rules. Please
also refer to the lexical rules emitted by the customization system.
Adjective agreement lexical rules should be of the "add only" type.
Note that if you have an apparently uninflected form (i.e., a zero in
the paradigm), you'll need to make sure it goes through a constant
lexical rule (no spelling change) which fills in the relevant feature
values.
Lexical rules
While it's possible to have position classes which include some information-adding lex rules and some information-changing lex rules, in general it's more common for the rules within the position class to be consistent on this point.
pernumtense-lex-rule-super := add-only-no-ccont-rule &
[ INFLECTED [ PERNUMTENSE-FLAG +,
NUM-FLAG #num ],
DTR verb-lex &
[ INFLECTED.NUM-FLAG #num ] ].
3sg-lex-rule := infl-lex-rule & pernumtense-lex-rule-super &
[ SYNSEM.LOCAL [ CAT.VAL.SUBJ.FIRST.LOCAL.CONT.HOOK.INDEX.PNG [ PER 3rd,
NUM sg ],
CONT.HOOK.INDEX.E.TENSE nonpast ] ].
3sg_verb := %suffix (!s !ss) (!ss !ssses) (ss sses) 3sg_verb-lex-rule.And here's the letter set that's used:
%(letter-set (!s abcedfghijklmnopqrtuvwxyz))
We are modeling the cognitive status attributed to discourse referents by particular referring expressions through a pair of features COG-ST and SPECI on ref-ind (the value of INDEX for nouns). Here is our first-pass guess at the cognitive status associated with various types of overt expressions (for dropped arguments, see below):
| Marker | COG-ST value | SPECI value |
|---|---|---|
| Personal pronoun | activ-or-more | + |
| Demonstrative article/adjective | activ+fam | |
| Definite article/inflection | uniq+fam+act | |
| Indefinite article/inflection | type-id |
If you have any overt personal pronouns, constrain their INDEX values to be [COG-ST activ-or-more, SPECI + ].
If you have any determiners which mark definiteness, have them constrain the COG-ST of their SPEC appropriately. For demonstrative determiners, see below.
If you have any nominal inflections associated with discourse status, implement lexical rules which add them and constrain the COG-ST value appropriately, or add COG-ST constraints to the lexical rules defined by the customization system.
Note that in some cases an unmarked form is underspecified, where in others it stands in contrast to a marked form. You should figure out which is the case for any unmarked forms in your language (e.g., bare NPs in a language with determiners, unmarked nouns in a language with definiteness markers), and constrain the unmarked forms appropriately. For bare NPs, the place to do this is the bare NP rule (note that you might have to create separate bare NP rules for pronouns v. common nouns in this case). For definiteness affixes, you'll want a constant-lex-rule that constrains COG-ST, and that is parallel to the inflecting-lex-rule that adds the affix for the overtly marked case.
Some languages have agreement for definiteness on adjectives. In this case, you'll want to add lexical rules for adjectives that constrain the COG-ST of the item on their MOD list.
Note This year you were not asked to systematically collect demonstratives, but some of you turned them up as part of your work on "the rest of the NP". These instructions are here in case you have demonstratives in your testsuite, but if you don't, you do not need to worry about this.
All demonstratives (determiners, adjectives and pronouns [NB: demonstrative pronouns are not on the todo list this year]) will share a set of relations which express the proximity to hearer and speaker. We will arrange these relations into a hierarchy so that languages with just a one- or two-way distinction can be more easily mapped to languages with a two- or three-way distinction. In order to do this, we're using types for these PRED values rather than strings. Note the absence of quotation marks. We will treat the demonstrative relations as adjectival relations, no matter how they are introduced (via pronouns, determiners, or quantifiers).
There are (at least) two different types of three-way distinctions. Here are two of them. Let me know if your language isn't modeled by either.
demonstrative_a_rel := predsort. proximal+dem_a_rel := demonstrative_a_rel. ; close to speaker distal+dem_a_rel := demonstrative_a_rel. ; away from speaker remote+dem_a_rel := distal+dem_a_rel. ; away from speaker and hearer hearer+dem_a_rel := distal+dem_a_rel. ; near hearer
demonstrative_a_rel := predsort. proximal+dem_a_rel := demonstrative_a_rel. ; close to speaker distal+dem_a_rel := demonstrative_a_rel. ; away from speaker mid+dem_a_rel := distal+dem_a_rel. ; away, but not very far away far+dem_a_rel := distal+dem_a_rel. ; very far away
Demonstrative adjectives come out as the easy case in this system. They are just like regular adjectives, except that in addition to introducing a relation whose PRED value is one of the subtypes of demonstrative_a_rel defined above, they also constrain the INDEX.COG-ST of their MOD value to be activ+fam.
Demonstrative determiners introduce two relations. This time, they are introducing the quantifier relation (Let's say "exist_q_rel") and the demonstrative relation. This analysis entails changes to the Matrix core, as basic-determiner-lex assumes just one relation being contributed. Accordingly, we are going to by-pass the current version of basic-determiner-lex and define instead determiner-lex-supertype as follows:
determiner-lex-supertype := norm-hook-lex-item & basic-zero-arg &
[ SYNSEM [ LOCAL [ CAT [ HEAD det,
VAL[ SPEC.FIRST.LOCAL.CONT.HOOK [ INDEX #ind,
LTOP #larg ],
SPR < >,
SUBJ < >,
COMPS < >]],
CONT.HCONS < ! qeq &
[ HARG #harg,
LARG #larg ] ! > ],
LKEYS.KEYREL quant-relation &
[ ARG0 #ind,
RSTR #harg ] ] ].
This type should have two subtypes (assuming you have demonstrative determiners as well as others in your language --- otherwise, just incorporate the constraints for demonstrative determiners into the type above).
Make sure your ordinary determiners in the lexicon inherit from the first subtype, and that your demonstrative determiners inherit from the second subtype. Demonstrative determiner lexical entries should constrain their LKEYS.ALTKEYREL.PRED to be an appropriate subtype of demonstrative_a_rel.
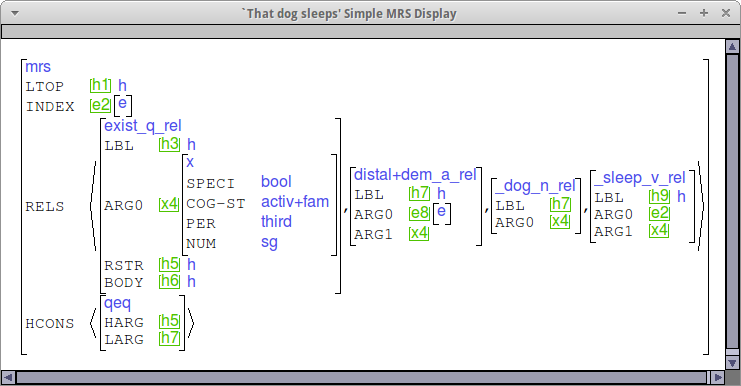
Here is a sample MRS showing what an NP with a demonstrative should look like. Note that whether the demonstrative_a_rel comes from a determiner or an adjective, it should end up looking the same. I have expanded the first instance of the variable x4 so that you can see the cog-st value.
The customization system includes an argument optionality library which we believe to be fairly thorough, regarding the syntax of optional arguments. The goal of this part of this lab therefore is to (a) fix up anything that is not quite right in the syntax and (b) try to model the semantics, and in particular, the cognitive status associated with different kinds of dropped arguments. Regarding (a), if the analysis provided by the customization system isn't quite working, post to GoPost and we'll discuss how to fix it with tdl editing.
Regarding (b), you need to do the following:
Note that the Matrix currently assumings that dropped subjects are always [COG-ST in-foc]. This may not be true, especially in various impersonal constructions. If it's not true for your language, please let me know.
Our goal is to come up with semantic representations like the following for possessives, where there is a poss_rel relating the two nouns, a quantifier for each (where the quantifier for the possessum is contributed by the possessive construction), and the possessed noun is marked as definite (i.g. [COG-ST uniq+fam+act]).
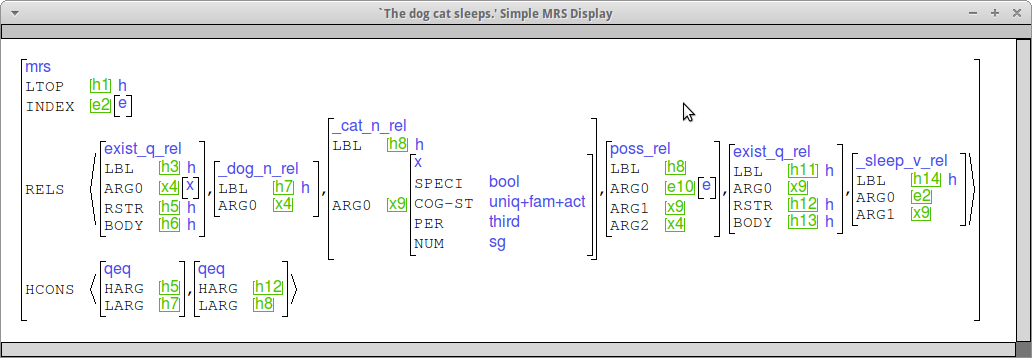
The poss_rel, quantifier and COG-ST constraint can be contributed by a linker word, a construction marking possessives via juxtaposition of the two NPs, or possessive pronouns (which we'll actually treat as determiners). In the case of morphological marking of possessors, most of the work will still be done by a construction like the one for juxtaposition.
For languages that mark possession by simple juxtaposition, we want a construction that takes a NOM as its head daughter (the possessum), an NP as its non-head daughter (the possessor), contributes the quantifier (exist_q_rel) for the NOM and the poss_rel via its C-CONT.RELS. The C-CONT.HOOK should expose the head daughter's INDEX.
Here is a sample rule definition for the case where the head daughter (possessum) is the second of the pair:
poss-phrase := head-final &
[ SYNSEM.LOCAL.CAT [ HEAD #head,
VAL [ SPR < >,
COMPS < >,
SUBJ < > ] ],
C-CONT [ HOOK.INDEX #index,
RELS < ! arg12-ev-relation & [ PRED "poss_rel",
LBL #lbl,
ARG1 #index,
ARG2 #poss ],
quant-relation & [ PRED "exist_q_rel",
ARG0 #index,
RSTR #harg ] ! >,
HCONS < ! qeq & [ HARG #harg, LARG #lbl ] ! >,
ICONS < ! ! > ],
HEAD-DTR.SYNSEM.LOCAL [ CAT [ HEAD #head & noun,
VAL.SPR < [ ] > ],
CONT.HOOK [ INDEX #index & [ COG-ST uniq+fam+act ],
LTOP #lbl ] ],
NON-HEAD-DTR.SYNSEM.LOCAL [ CAT [ HEAD noun,
VAL.SPR < > ],
CONT.HOOK.INDEX #poss ] ].
This analysis predicts that when posession is marked by juxtaposition, the possessor is always at the edge of the NP (i.e. no further modifiers of the head noun can occur outside the possessor). If you language is a counterexample to this, let me know!
Despite the name, these will actually be treated as determiners. In addition to the exist_q_rel, they will contribute the poss_rel, as well as a pron_rel and associated exist_q_rel for the possessor, and constrain the COG-ST on both roles. The lexical entries for particular possessive pronouns will constrain the PNG information on the possessor.
Sample tdl, first types:
determiner-lex-supertype := norm-hook-lex-item & norm-zero-arg & non-mod-lex-item &
[ SYNSEM [ LOCAL [ CAT [ HEAD det,
VAL [ SPEC.FIRST.LOCAL.CONT.HOOK [ INDEX #ind,
LTOP #larg ],
SPR < >,
SUBJ < >,
COMPS < >]],
CONT.HCONS.LIST.FIRST qeq &
[ HARG #harg,
LARG #larg ] ],
LKEYS.KEYREL quant-relation &
[ ARG0 #ind,
RSTR #harg ] ] ].
poss-pron-det-lex := determiner-lex-supertype &
[ SYNSEM [ LOCAL [ CAT.VAL.SPEC < [ LOCAL.CONT.HOOK [ INDEX #arg1 &
[ COG-ST uniq+fam+act ],
LTOP #lbl ]] >,
CONT [ RELS < ! [ PRED "exist_q_rel" ],
arg12-ev-relation &
[ PRED "poss_rel",
LBL #lbl,
ARG1 #arg1,
ARG2 #arg2 ],
quant-relation &
[ PRED "exist_q_rel",
ARG0 #arg2,
RSTR #harg ],
#altkeyrel ! >,
HCONS < ! [ ], qeq & [ HARG #harg,
LARG #lbl2 ] ! > ] ],
LKEYS.ALTKEYREL #altkeyrel & noun-relation &
[ PRED "pron_rel",
LBL #lbl2,
ARG0 #arg2 & [ COG-ST activ-or-more,
SPECI + ] ] ] ].
And then a lexical entry:
my := poss-pron-det-lex &
[ STEM < "my" >,
SYNSEM.LKEYS.ALTKEYREL.ARG0.PNG.PERNUM 1sg ].
If possessive pronouns only combine with possessum nouns with a certain inflected form, that can be taken care of with a lexical rule to produce the inflected form that constrains some feature on the HEAD of the inflected noun (maybe CASE, if the language has a case system).
The analysis here uses the juxtaposition construction given above, in combination with a lexical rule that produces the possessive-marked form. This lexical rule should constrain some value on the HEAD of the noun (e.g. CASE, if there's a case system in the language) and the juxtaposition rule should be modified to select for that. Note that unlike the sample tdl for the juxtaposition construction above, this analysis entails that the phrase cannot be headed.
If the inflection on the possessum reflects the person/number/gender of the possessor, this can be handled by having the lexical rules constrain the INDEX.PNG of the SPEC of the head noun. At this point, the juxtaposition rule should identify the head's SPEC..INDEX with the non-head daughter's HOOK.INDEX.
This analysis predicts that the inflection on the possessum will never reflect non-semantic properties (e.g. case) of the possessor. If your language is an exception to this, please let me know.
Again, the analysis here uses the juxtaposition construction given above, in combination with a lexical rule that produces the possessive-marked form. This lexical rule should constrain some value on the HEAD of the noun (e.g. CASE, if there's a case system in the language) and the juxtaposition rule should be modified to select for that.
If the inflection on the possessor noun reflects the person/number/gender of the possessum, this can be handled by having the lexical rules constrain the INDEX.PNG of the SPR of the infleted noun. At this point, the juxtaposition rule should identify the non-head's SPR..INDEX with the head daughter's HOOK.INDEX.
If the inflection on the possessor noun reflects the person/number/gender of the possessor, this can be directly constrained on the daughter of the lexical rule itself.
This is the case that we find in English (with the clitic 's) or Japanese (with the 'particle' no). These words combine with the possessor noun (as a specifier or complement) and contribute the poss_rel. The constituent that they build can either serve as a modifier of the noun (in the Japanese case, where other modifiers can occur outside the possessive phrase) or as a determiner (English where the possessive is at the edge of the NP).
Sample tdl, for English-style possessive determiner. NB: Making this work required taking the constraint [SPEC < >] off of noun-lex and loosening the lenght of the HCONS list on determiner-lex-supertype (compared to what's given for that type above).
poss-det-lex := determiner-lex-supertype & [ SYNSEM [ LOCAL [ CAT.VAL [ SPR < [ LOCAL [ CAT [ HEAD noun, VAL.SPR < > ], CONT.HOOK.INDEX #arg2 ] ] >, SPEC < [ LOCAL.CONT.HOOK [ INDEX #arg1 & [ COG-ST uniq+fam+act ], LTOP #lbl ]] > ], CONT [ RELS < ! [ PRED "exist_q_rel" ], arg12-ev-relation & [ PRED "poss_rel", LBL #lbl, ARG1 #arg1, ARG2 #arg2 ] ! >, HCONS < ! [ ] ! > ] ] ] ].
Sample tdl, for Japanese-style possessive adposition. I've spelled in of in the lexical entry here, even though I don't think it's exactly correct to say that of in English contributes poss_rel.
Type:
adposition-lex := basic-adposition-lex & intersective-mod-lex & norm-ltop-lex-item & [ SYNSEM [ LKEYS.KEYREL [ ARG0 #arg0, ARG1 #xarg, ARG2 #ind ], LOCAL [ CONT.HOOK [ XARG #xarg, INDEX #arg0 ], CAT [ HEAD.MOD < [ LOCAL [ CAT [ HEAD noun, VAL.SPR cons ], CONT.HOOK.INDEX #xarg ]] >, VAL [ SPR < >, COMPS < [ LOCAL [ CAT [ HEAD noun, VAL.SPR < > ], CONT.HOOK.INDEX #ind ]] >, SUBJ < > ]]]]].
Lexical entry:
of := adposition-lex &
[ STEM < "of" >,
SYNSEM.LKEYS.KEYREL [ PRED "poss_rel",
ARG1.COG-ST uniq+fam+act ] ].
In order to get a sense of the coverage of our grammars over naturally occurring text, we are going to collect small test corpora. Minimally, these should consist of 10-20 sentences from running text. They could be larger; however, that is not recommended unless:
Note: 1,000 sentences is the maximum practical size for any single [incr tsdb()] skeleton. You could of course split your test corpus over multiple skeletons, but I'd be surprised if anyone got close to 1,000 sentences!
Note also that our grammars won't cover anything without lexicon. If you have access to a digitized lexical resource that you can import lexical items from, you can address this to a certain extent. Otherwise, you'll want to limit your test corpus to a size that you are willing to hand-enter vocabulary for. (If you have access to a Toolbox lexicon for your language, contact me about importing via the customization system.)
For Lab 5, your task is to locate your test corpus (10-20 sentences will be sufficient, more only if you want and you have access to the resources described above) and format it for [incr tsdb()]. If you have IGT to work with in the first place, it may be convenient to use the make_item script to create the test corpus skeleton. (Note that you want this to be separate from your regular test suite skeleton.) Otherwise, you can use [incr tsdb()]'s own import tool (File | Import | Test items) which expects a plain text file with one item per line. The result of that command is a testsuite profile from which you'll need to copy the item (and relations) file to create a testsuite skeleton.
Check list:
For each of the following phenomena, please include the following your write up:
In addition, your write up should include a statement of the current coverage of your grammar over your test suite (using numbers you can get from Analyze | Coverage and Analyze | Overgeneration in [incr tsdb()]) and a comparison between your baseline test suite run and your final one for this lab (see Compare | Competence).
Finally please briefly describe your test corpus, including: where you collected it, how many sentences it contains, and what format (transliterated, etc) it is in.
svn export yourgrammar iso-lab5For git, please do the equivalent.
tar czf iso-lab5.tgz iso-lab5