As usual, check the write up instructions first.
There are several places in this lab
where I ask you to contact me if your grammar requires information
not in these instructions. Please read through this lab by class on
Tuesday, preferably earlier, so we can start that conversation in a timely fashion.
Requirements for this assignment
Before making any changes to your grammar for this lab, run a baseline test suite instance. If you decide to add items to your test suite for the material covered here, consider doing so before modifying your grammar so that your baseline can include those examples. (Alternatively, if you add examples in the course of working on your grammar and want to make the snapshot later, you can do so using the grammar you turned in for Lab 5.)
The semantics for declarative and interrogative clauses will be the same except for the value of the feature SF (sentential force) on the event index of the main predicate.
The customization script may have provided the right kind of syntax and semantics for matrix yes-no questions already. Try parsing an example from your test suite. If it parses, examine the MRS. Is the value of SF on the INDEX of the clause ques? (Or in the case of intonation questions only, do you get prop-or-ques?)
If your yes-no question doesn't parse, or if it does but not with the right semantics, contact me, and we will work out what needs to be done.
Some languages mark questions with an element (often a clitic) that goes right after the element that is the focus of the question and sometimes further requires that element to be the first thing in the sentence.
The general idea is that the question clitics are modifiers that attach to the right of the word they modify, and insist that that word be the initial thing in the sentence. The first step, therefore, is to add the feature which will check the position in the sentence. It turns out that this is rather involved, but the following worked for Russian and a handful of other languages.
canonical-synsem :+ [ L-PERIPH bool ].
(I'm leaving open for now the possibility that we might want a mirror-feature R-PERIPH.)
basic-binary-phrase :+ [ SYNSEM.L-PERIPH #periph, ARGS < [ SYNSEM.L-PERIPH #periph ], [SYNSEM.L-PERIPH -] > ].
basic-head-mod-phrase-simple :+
[ HEAD-DTR.SYNSEM.L-PERIPH #periph,
NON-HEAD-DTR.SYNSEM.LOCAL.CAT.HEAD.MOD < [ L-PERIPH #periph ] > ].
same-periph-unary-phrase := unary-phrase & [ SYNSEM.L-PERIPH #periph, ARGS < [ SYNSEM.L-PERIPH #periph ] > ].
question-clitic-lex := no-hcons-lex-item &
[ SYNSEM.LOCAL [ CAT [ VAL [ SPR < >, COMPS < >, SUBJ < >, SPEC < >],
HEAD adv &
[ MOD < [ LIGHT +,
LOCAL intersective-mod,
L-PERIPH + ] > ]],
CONT.RELS <! !> ]].
arda_gr := generator_rule &
[ CONTEXT.RELS <! [ ARG0.SF ques ] !>,
FLAGS.TRIGGER "LEX-ID-HERE" ].
s-coord-phrase :+
[ SYNSEM.LOCAL.CAT.MC bool,
LCOORD-DTR.SYNSEM.LOCAL.CAT.MC bool,
RCOORD-DTR.SYNSEM.LOCAL.CAT.MC bool ].
s-bottom-coord-phrase :+
[ SYNSEM.LOCAL.CAT.MC bool,
NONCONJ-DTR.SYNSEM.LOCAL.CAT.MC bool ].
That should be enough to get the question clitic appearing in the right place. When you've done this much, stop and check. And of course post to Canvas if it's not working :). While you're testing, make sure that the LIGHT value of the constituent containing the quesiton clitic and the thing to its left is - ... otherwise, this will spin on generation. If it's not [ LIGHT - ], then post to Canvas and we'll figure out how to make sure that it is.
The goal of the second part of the analysis is to correlate question semantics ([SF ques]) with the presence of a clitic in the clause. For Russian, at least, we need to allow the clitics to appear in embedded as well as matrix clauses, with the clause bearing the clitic being the one that's expressing a question.
The central idea here is for the question clitics to register their presence in a non-local feature, which is accumulated from both daughters. I wanted to use the feature QUE for this, but it seems that matrix.tdl includes some English-specific constraints regarding QUE in head-modifier constructions. For now, we'll work around by adding a new non-local feature YNQ. There will be a non-branching rule (int-cl) which empties the YNQ list and returns L-PERIPH to underspecified, so that the clitics can appear in embedded clauses. Because we need to make sure that the int-cl rule applies at the top of the clause, we'll be (ab)using MC a bit: The rest of the rules will say [MC na] (not-applicable) on the mother, and insist on [MC na] on the head-daughter. The int-cl rule (and a parallel decl-cl rule that this requires) will say [MC bool], compatible with the root condition ([MC +]) and the complement position of clause embedding verbs ([MC -]).
This entails the following changes:
non-local :+ [ YNQ 0-1-dlist ].
basic-binary-phrase :+
[ SYNSEM.NON-LOCAL.YNQ [ LIST #list,
LAST #last ],
ARGS < [ SYNSEM.NON-LOCAL.YNQ [ LIST #list,
LAST #middle ]],
[ SYNSEM.NON-LOCAL.YNQ [ LIST #middle,
LAST #last ]] > ].
same-ynq-unary-phrase := unary-phrase &
[ SYNSEM.NON-LOCAL.YNQ #ynq,
ARGS < [ SYNSEM.NON-LOCAL.YNQ #ynq ] > ].
question-clitic-lex := no-hcons-lex-item &
[ SYNSEM [ LOCAL [ CAT [ VAL [ SPR < >, COMPS < >, SUBJ < >, SPEC < >],
HEAD adv &
[ MOD < [ LIGHT +,
L-PERIPH + ] > ]],
CONT.RELS <! !> ],
NON-LOCAL.YNQ <! *top* !> ]].
non-ynq-word := word-or-lexrule & [ SYNSEM.NON-LOCAL.YNQ 0-dlist ]. basic-zero-arg :+ non-ynq-word. basic-one-arg :+ non-ynq-word. basic-two-arg :+ non-ynq-word. basic-three-arg :+ non-ynq-word. intersective-mod-lex :+ non-ynq-word.
root := phrase &
[ SYNSEM [ LOCAL [ COORD -,
CAT [ VAL [ SUBJ < >,
COMPS < > ],
MC +,
HEAD +vc &
[ FORM finite ] ] ],
NON-LOCAL.YNQ 0-dlist ] ].
int-cl := head-only & interrogative-clause &
[ SYNSEM [ LOCAL.CAT [ VAL #val,
MC bool ],
NON-LOCAL.YNQ <! !> ],
HEAD-DTR.SYNSEM [ LOCAL.CAT [ MC na,
VAL #val ],
NON-LOCAL.YNQ <! *top* !> ]].
decl-cl := head-only & declarative-clause & same-ynq-unary-phrase &
[ SYNSEM.LOCAL.CAT [ VAL #val,
MC bool ],
HEAD-DTR.SYNSEM [ LOCAL.CAT [ MC na,
VAL #val ],
NON-LOCAL.YNQ 0-dlist ]].
mc-na-headed-phrase := headed-phrase &
[ SYNSEM.LOCAL.CAT.MC na,
HEAD-DTR.SYNSEM.LOCAL.CAT.MC na ].
binary-headed-phrase :+ mc-na-headed-phrase.
We will be using clausal complements as our example of embedded clauses. To do so, we need to create clause-embedding verbs. First, if you haven't already, find examples of verbs that can embed propositions and verbs that can embed questions. If you also find verbs that are happy to embed either, we can make use of them. For inspiration, you can look here or here.
If your matrix and embedded clauses look the same, you should be able to test this immediately. Otherwise, you'll have to wait until you've implemented the syntax for your embedded clauses. (Though to test the semantics, you could say that the COMPS value of the verb is an S, and try an example where a matrix clause appears in that complement position.)
Some languages mark embedded clauses (declaractive, interrogative or both) with complementizers (e.g., that and whether in English). To implement this, you'll need to do the following. (If your language also marks matrix questions with a question particle, you have some of the following in your grammar already.)
Test your embedded clauses. Do they parse as expected? Can you still generate?
Note: You'll need to add trigger rules for any complementizers, since they do not contribute any eps on their RELS list. Here is an example for a complementizer that goes with embedded declaratives: (And if you have other semantically empty things, contact me about designing trigger rules for them, too.)
comp_gtr := generator_rule &
[ CONTEXT [ RELS <! [ ARG2 #h & handle ],
[ ARG0 #e & event ] !> ],
FLAGS [ EQUAL < #e, #h >,
TRIGGER "name_of_comp_entry" ]].
Other possible syntactic differences between main and subordinate clauses include:
Consult with me to work out an analysis for whatever your language is doing in this case.
If your matrix and embedded clauses have different syntactic properties (e.g., presence v. absence of complementizers), you'll need to constrain things so that the embedded clause syntax only appears in embedded clauses and vice versa for matrix clause syntax. There are three resources for doing so:
If the difference is strictly S v. CP, you don't need the feature MC. Otherwise, you probably will need all three: The root condition will require [MC +], the embedding verb will require [MC -], and the constructions/lexical rules/etc which create the embedded and matrix clauses themselves should set appropriate values for MC.
Be sure your test suite contains negative examples illustrating
matrix clause syntax in embedded clauses and vice versa.
Check your MRSs
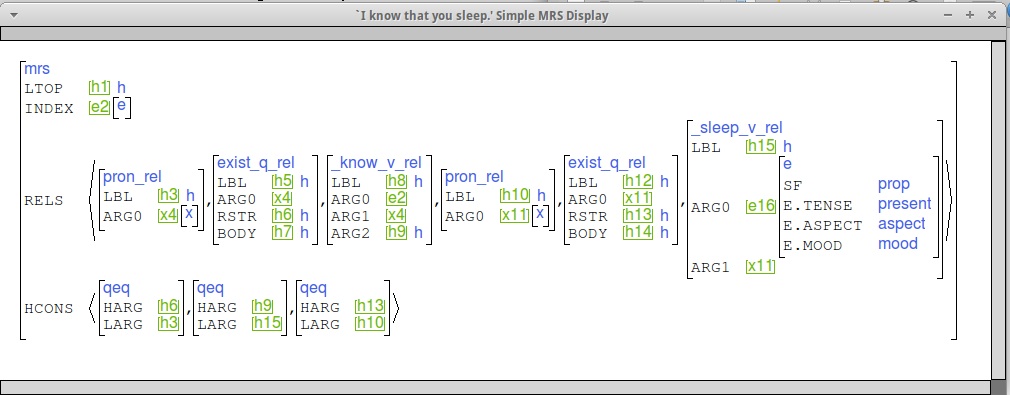
Here are some examples to give you an idea of what we're looking for. (This is the "indexed MRS" view.)
Note the qeq linking the ARG2 position
of _know_v_rel (h9) to the LBL of _sleep_v_rel (h15),
and the SF value of e16 (PROP).
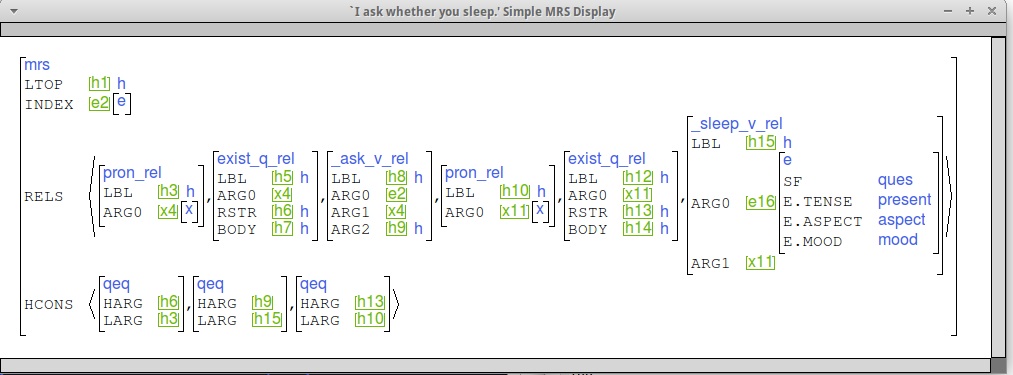
Note the qeq linking the ARG2 position
of _ask_v_rel (h9) to the LBL of _sleep_v_rel (h15),
and the SF value of e16 (QUES).
The goal of this part of this lab is to extend the grammars to cover sentences where the main (semantic) predicate is not a verb, i.e., NP, PP, and AP predicates. In some languages (including English) such predicates require the "support" of a particular bleached verb (the copula, or perhaps a verb of location). In others, they can serve as predicates on their own. In still other languages, we find a mix: The copula (or other verb) is required for certain types of predicates or in certain tenses but not others. Or the copula (or other verb) is optional: possible but not required.
It's also possible that in some languages the copula is optional in matrix clauses but required in embedded clauses. I haven't found an example like this yet, but I'd be curious to know about it if you find one.
Note that in some languages, NPs inflected for locative case (or similar) function like locative PPs in other languages.
Some of your grammars have adpositions already, but few, if any, have semantically contentful adpositions. You'll need to define these for this lab. The matrix provides a type basic-int-mod-adposition-lex, which should have most of the information required. Define a subtype with appropriate constraints on the MOD and VAL values, and try it out to see what else you might need to add.
We analyze copulas as semantically empty auxiliaries. You may already have a type very similar to this, perhaps from the adjectives library. The tdl for a copula should look something like this:
copula-verb-lex := verb-lex-supertype & trans-first-arg-raising-lex-item-2 &
[ SYNSEM.LOCAL [ CAT.VAL [ SUBJ < #subj >,
COMPS < #comps >,
SPR < >,
SPEC < > ],
CONT.HOOK.XARG #xarg ],
ARG-ST < #subj &
[ LOCAL [ CONT.HOOK.INDEX #xarg,
CAT [ VAL [ SPR < >,
COMPS < > ],
HEAD noun ] ] ],
#comps &
[ LOCAL.CAT [ VAL [ COMPS < > ],
HEAD +jp ] ] > ].
You may also need to create verb-lex-supertype which inherits from some of the types that your verb-lex type does, but not all of them. In particular, you want to get the types that give it access to whatever verbal morphology is relevant, as well as constraining it to be [HEAD verb].
The constraint [HEAD +jp] on the complement specifies that the complement should be (headed by) an adjective or an adposition. Depending on where copulas are required in your language, you might want to change this. If you need to give adjectives or adpositions non-empty SUBJ lists (e.g., because they can be stand-alone predicates in some cases; see below), then you'll also want to constrain the COMPS's SUBJ to be < [ ] > (aka cons) to make sure that the subject isn't realized twice.
Note that the copula verb uses the XARG to do the linking (the relevant constraint is declared on the supertype trans-first-arg-raising-lex-item in matrix.tdl). This means that the adjectives and adpositions will need to link their ARG1 to their XARG. This should already be the case, but you should double check.
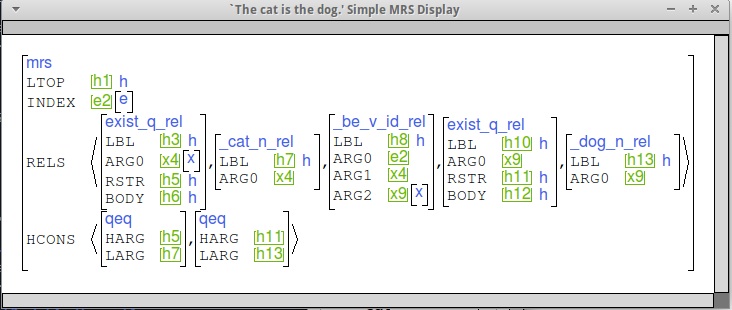
We will follow the ERG in positing a different copula for use with NP predicates. This is because we don't want to give every noun a semantic argument position for a potential subject. The copula verb for NP predicates will instead introduce an elementary predication linking its subject and complement.
This means that in many languages, this copula might just be an ordinary transitive verb. It's not in English, because it also has auxiliary properties. If the NP-predicate-supporting-copula in your language differs in its behavior from (other) transitive verbs, post to Canvas.
The PRED value for this verb should be "_be_v_id_rel".
For languages that express meanings like in the park with locative NPs (i.e. no adposition), we will write a non-branching phrase structure rule that builds a PP out of locative case NP. You'll also need a lexical rule creating the right form of the NP and constraining it to be [CASE loc] (or whatever you called your locative case). This lexical rule should fit into the same position class as your other case lexical rules.
Here is a sample PP over NP rule, from the Marathi grammar from 2014. This rule uses C-CONT to introduce the locative relation.
Note that this rule builds PPs that can either be the complement of a copula or function as modifiers of verbal projections. Locative NPs as stand-alone predicates would need a non-empty SUBJ value, with an NP on it, whose INDEX is identified with #xarg and whose CASE value is constrained as appopriate. Similarly, if your locative NPs can't be adverbial modifiers, then the mother of this rule should have an empty MOD list.
[Note added Feb 2018: This rule also needs to identify the LBL and ARG1 of the _loc_p_rel with the INDEX and LTOP of the MOD element.]
locative-pp-phrase := unary-phrase &
[ SYNSEM [ LOCAL.CAT [ HEAD adp & [ MOD < [ LOCAL intersective-mod &
[ CAT.HEAD verb ] ] > ],
VAL [ COMPS < >,
SUBJ < >,
SPR < > ]]],
C-CONT [ HOOK [ LTOP #ltop,
INDEX #index,
XARG #xarg ],
RELS <! arg12-ev-relation &
[ PRED "_loc_p_rel",
LBL #ltop,
ARG0 #index,
ARG1 #xarg,
ARG2 #dtr ] !>,
HCONS <! !> ],
ARGS < [ SYNSEM.LOCAL [ CAT [ HEAD noun & [CASE loc],
VAL.SPR < > ],
CONT.HOOK [ INDEX #dtr ]]] > ].
locative-verb-lex := verb-lex & trans-first-arg-control-lex-item &
[ SYNSEM.LOCAL [ CAT.VAL [ SUBJ < #subj >,
COMPS < #comps >,
SPR < >,
SPEC < > ],
CONT.HOOK.XARG #xarg ],
ARG-ST < #subj &
[ LOCAL [ CONT.HOOK.INDEX #xarg,
CAT [ VAL [ SPR < >,
COMPS < > ],
HEAD noun ] ] ],
#comps &
[ LOCAL.CAT [ VAL [ COMPS < > ],
HEAD adp ] ] > ].
Note that there are many share constraints between this and copula-verb-lex. If you have both, please make a supertype for the shared constraints.
The lexical entry for the locative verb can introduce "_be+located_v_rel" as its LKEYS.KEYREL.PRED.
If you have a locative verb that takes NP complements, then it is best analyzed as a simple transitive verb with the PRED value "_be+located_v_rel".
If your language allows APs and PPs as stand-alone predicates, the basic strategy is to modify the selecting contexts for sentences (initial symbol, clause embedding verbs) to generalize the requirements on HEAD. This needs to be done slightly differently depending on how tense/aspect are marked in these clauses.
For locative NPs as stand-alone predicates, modify the PP over NP rule introduced above to have a non-empty SUBJ list, as noted.
Note that some languages don't have adjectives at all, just a class of stative intransitive verbs. For present purposes, the definitive test is what happens when these elements modify nouns. If they appear to enter the same construction as relative clauses headed by transitive verbs (and non-stative intransitives), then they're just verbs. However, for the purposes of the MT exercise, it will be helpful to have their PRED values end in _a_rel, rather than _v_rel.
The first step is to get from the attributive entries for As or Ps (or both) to predicative uses. It may be possible to use one and the same lexical entry in both uses. To enable predicative uses, your As or Ps (or both) need to have non-empty SUBJ lists. The sole element of the SUBJ list should be an NP or PP as appropriate (with appropriate constraints on its CASE value), and share its INDEX with the XARG and ARG1 of the A/P. (This index sharing is the same as with the MOD value.)
Finally, if some but not all As or Ps can serve as predicates, you can handle this by declaring a new feature, PRD, on the type head. Make the attributive-only As/Ps [PRD -], and any predicative-only ones [PRD +]. Then edit the root condition to require [PRD +]. This can also be useful if you have different inflection for predicative v.\ attributive uses of adjectives.
head :+ [ PRD bool ].
If an AP or PP stand-alone predicate has underspecified tense and aspect (i.e., can be used in any tense/aspect context) or if it actually takes tense/aspect markers directly, then you can allow for AP or PP predicates by redefining the selecting contexts. In particular:
Note that even if it is possible to use a copula for, e.g., past tense AP/PP predicate sentences, you might still have unrestricted tense/aspect on the copulaless counterparts of these sentences. The key question is whether the copulaless sentences are necessarily interpreted as having a particular tense/aspect value. If so, see the next section.
Finally, we come to the case of (non-locative) NPs used as predicates without any supporting verb. As with NPs used as the complement of a copula, we need to do something to get an extra predication in. Here, I think the best solution is a non-branching non-headed phrase structure rule which takes an NP daughter and produces a VP mother. It should introduce the "_be_v_id_rel" relation through the C-CONT.RELS, linking the C-CONT.INDEX to the ARG0 of this relation. If NPs as stand-alone predicates necessarily get present tense interpretation, this rule can also fill in that information.
Here is a version of the rule we worked out in class for Halkomelem in 2013. Note that in Halkomelem (hur), the nouny predicates are actually N-bars. This means the rule has to fill in the quantifier rel as well as the "_be_v_id_rel".
n-bar-predicate-rule := unary-phrase & nocoord &
[ SYNSEM.LOCAL.CAT [ HEAD verb,
VAL [ COMPS < >,
SUBJ < [ LOCAL [ CONT.HOOK.INDEX #arg1,
CAT [ HEAD noun,
VAL.SPR < > ] ] ] > ] ],
C-CONT [ HOOK [ LTOP #ltop,
INDEX #index,
XARG #arg1 ],
RELS <! arg12-ev-relation &
[ PRED "_be_v_id_rel",
LBL #ltop,
ARG0 #index,
ARG1 #arg1,
ARG2 #arg2 ],
quant-relation &
[ PRED "exist_q_rel",
ARG0 #arg2,
RSTR #harg ] !>,
HCONS <! qeq & [ HARG #harg, LARG #larg ] !> ],
ARGS < [ SYNSEM.LOCAL [ CAT [ HEAD noun,
VAL.SPR cons ],
CONT.HOOK [ INDEX #arg2,
LTOP #larg ]]] > ].
If you also need a non-branching rule for tense-restricted PP or AP predicates, you might consider doing those the same way (VP over PP/AP), and sharing many constraints between the two rules. Note, however, that the PP/AP rule would have an empty C-CONT.RELS list.
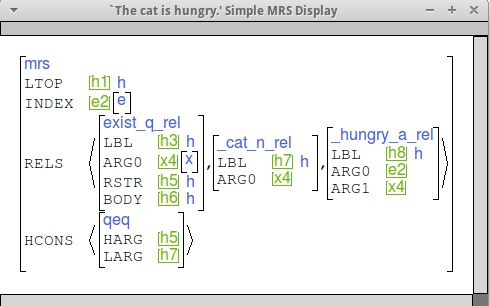
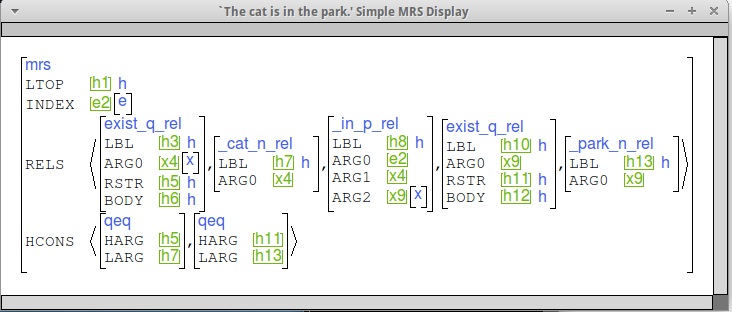
Here are some sample MRSs to give you a sense of what we're looking for. Note that yours might differ in detail, because of e.g., different tense values or the use of a locative verb.
For each of the following phenomena, please include the following your write up:
In addition, your write up should include a statement of the current coverage of your grammar over your test suite (using numbers you can get from Analyze | Coverage and Analyze | Overgeneration in [incr tsdb()]) and a comparison between your baseline test suite run and your final one for this lab (see Compare | Competence).
svn export yourgrammar iso-lab6For git, please do the equivalent.
tar czf iso-lab6.tgz iso-lab6