These instructions might get edited a bit over the next couple of days. I'll try to flag changes.
As usual, check the write up instructions first.
Requirements for this assignment
Before making any changes to your grammar for this lab,
run a baseline test suite instance. If you decide to add
items to your test suite for the material covered here, consider
doing so before modifying your grammar so that your baseline can
include those examples. (Alternatively, if you add examples
in the course of working on your grammar and want to make the
snapshot later, you can do so using the grammar you turned
in for Lab 4.)
Labs 2-4 fix-ups
This section requires posting to Canvas by Tuesday, preferably earlier.
Based on my feedback from Labs 2-4, propose something about your grammar to fix. Post this proposal to Canvas (by Tuesday), and I will reply with suggestions about how to go about fixing it and/or let you know that what you've picked is too complicated.
If you are also doing demonstratives/definiteness and cognitive status on optional arguments, you only need to post one thing to fix. If you aren't doing one or both of these, replace each you aren't doing with one other thing-to-fix. In other words, every group will proose one-three things to fix, and every group will have four phenomena handled in this lab (including adverbs, above).
The Matrix distinguishes scopal from intersective modification. We're going to pretend that everything is intersective and just not worry about the scopal guys for now (aside from negative adverbs, if you got one from the customization system).
head-adj-int := head-adj-int-phrase. adj-head-int := adj-head-int-phrase.
+nvcdmo :+ [ MOD < > ].
That adds the constraint [MOD < > ] to the type +nvcdmo, which is the supertype of all the head types other than adj and adv. (Notes: You might already have this constraint or a functionally equivalent one if your customized grammar includes adverbial negation, or from the adjectives library. Constraining +nvcdmo isn't necessarily the best way to do this, as you might want to allow nouny or verby things to be modifiers. The alternative is to constrain the relevant lexeme types to have empty MOD values.)
adverb-lex := basic-adverb-lex & intersective-mod-lex & [ SYNSEM [ LOCAL [ CAT [ HEAD.MOD < [ LOCAL.CAT.HEAD verb ]>, VAL [ SPR < >, SUBJ < >, COMPS < >, SPEC < > ]]]]].
The modifiers you are adding should share their LBL with the verb/noun they modify and take the ARG0 of the modifiee as their ARG1. Here are some examples that should what this looks like. (This is the "simple MRS" view.)
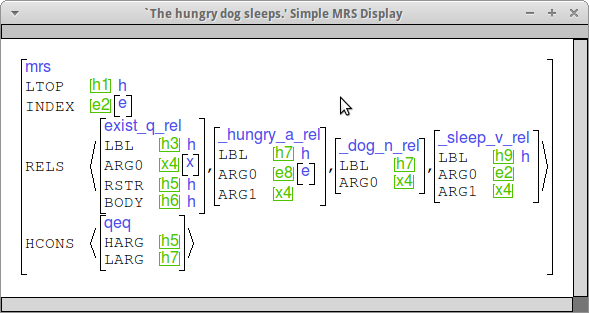
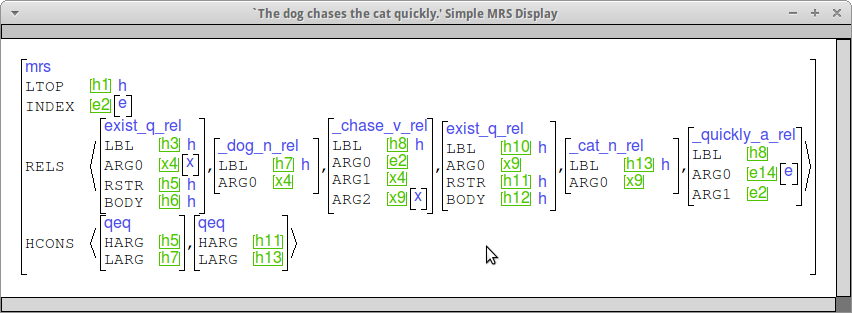
We are modeling the cognitive status attributed to discourse referents by particular referring expressions through a pair of features COG-ST and SPECI on ref-ind (the value of INDEX for nouns). Here is our first-pass guess at the cognitive status associated with various types of overt expressions (for dropped arguments, see below):
| Marker | COG-ST value | SPECI value |
|---|---|---|
| Personal pronoun | activ-or-more | + |
| Demonstrative article/adjective | activ+fam | |
| Definite article/inflection | uniq+fam+act | |
| Indefinite article/inflection | type-id |
If you have any overt personal pronouns, constrain their INDEX values to be [COG-ST activ-or-more, SPECI + ].
If you have any determiners which mark definiteness, have them constrain the COG-ST of their SPEC appropriately. For demonstrative determiners, see below.
If you have any nominal inflections associated with discourse status, implement lexical rules which add them and constrain the COG-ST value appropriately, or add COG-ST constraints to the lexical rules defined by the customization system.
Note that in some cases an unmarked form is underspecified, where in others it stands in contrast to a marked form. You should figure out which is the case for any unmarked forms in your language (e.g., bare NPs in a language with determiners, unmarked nouns in a language with definiteness markers), and constrain the unmarked forms appropriately. For bare NPs, the place to do this is the bare NP rule (note that you might have to create separate bare NP rules for pronouns v. common nouns in this case). For definiteness affixes, you'll want a constant-lex-rule that constrains COG-ST, and that is parallel to the inflecting-lex-rule that adds the affix for the overtly marked case.
Some languages have agreement for definiteness on adjectives. In this case, you'll want to add lexical rules for adjectives that constrain the COG-ST of the item on their MOD list.
Note This year you were not asked to systematically collect demonstratives, but some of you turned them up as part of your work on "the rest of the NP". These instructions are here in case you have demonstratives in your testsuite, but if you don't, you do not need to worry about this.
All demonstratives (determiners, adjectives and pronouns [NB: demonstrative pronouns are not on the todo list this year]) will share a set of relations which express the proximity to hearer and speaker. We will arrange these relations into a hierarchy so that languages with just a one- or two-way distinction can be more easily mapped to languages with a two- or three-way distinction. In order to do this, we're using types for these PRED values rather than strings. Note the absence of quotation marks. We will treat the demonstrative relations as adjectival relations, no matter how they are introduced (via pronouns, determiners, or quantifiers).
There are (at least) two different types of three-way distinctions. Here are two of them. Let me know if your language isn't modeled by either.
demonstrative_a_rel := predsort. proximal+dem_a_rel := demonstrative_a_rel. ; close to speaker distal+dem_a_rel := demonstrative_a_rel. ; away from speaker remote+dem_a_rel := distal+dem_a_rel. ; away from speaker and hearer hearer+dem_a_rel := distal+dem_a_rel. ; near hearer
demonstrative_a_rel := predsort. proximal+dem_a_rel := demonstrative_a_rel. ; close to speaker distal+dem_a_rel := demonstrative_a_rel. ; away from speaker mid+dem_a_rel := distal+dem_a_rel. ; away, but not very far away far+dem_a_rel := distal+dem_a_rel. ; very far away
Demonstrative adjectives come out as the easy case in this system. They are just like regular adjectives, except that in addition to introducing a relation whose PRED value is one of the subtypes of demonstrative_a_rel defined above, they also constrain the INDEX.COG-ST of their MOD value to be activ+fam.
Demonstrative determiners introduce two relations. This time, they are introducing the quantifier relation (Let's say "exist_q_rel") and the demonstrative relation. This analysis entails changes to the Matrix core, as basic-determiner-lex assumes just one relation being contributed. Accordingly, we are going to by-pass the current version of basic-determiner-lex and define instead determiner-lex-supertype as follows:
determiner-lex-supertype := norm-hook-lex-item & basic-zero-arg &
[ SYNSEM [ LOCAL [ CAT [ HEAD det,
VAL[ SPEC.FIRST.LOCAL.CONT.HOOK [ INDEX #ind,
LTOP #larg ],
SPR < >,
SUBJ < >,
COMPS < >]],
CONT.HCONS <! qeq &
[ HARG #harg,
LARG #larg ] !> ],
LKEYS.KEYREL quant-relation &
[ ARG0 #ind,
RSTR #harg ] ] ].
This type should have two subtypes (assuming you have demonstrative determiners as well as others in your language --- otherwise, just incorporate the constraints for demonstrative determiners into the type above).
Make sure your ordinary determiners in the lexicon inherit from the first subtype, and that your demonstrative determiners inherit from the second subtype. Demonstrative determiner lexical entries should constrain their LKEYS.ALTKEYREL.PRED to be an appropriate subtype of demonstrative_a_rel.
Here is a sample MRS showing what an NP with a demonstrative should look like. Note that whether the demonstrative_a_rel comes from a determiner or an adjective, it should end up looking the same. I have expanded the first instance of the variable x4 so that you can see the cog-st value.
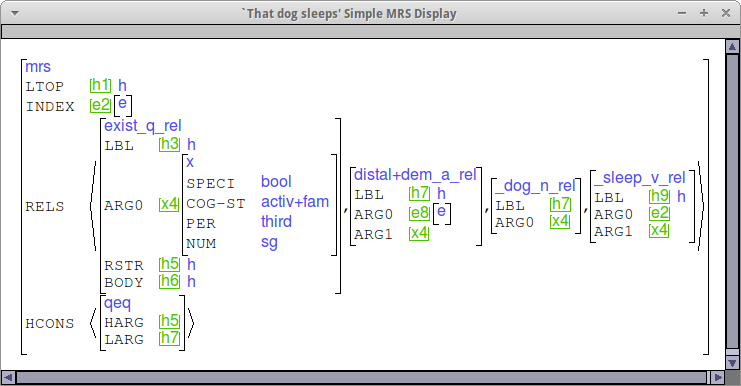
The customization system includes an argument optionality library which we believe to be fairly thorough, regarding the syntax of optional arguments. The goal of this part of this lab therefore is to (a) fix up anything that is not quite right in the syntax and (b) try to model the semantics, and in particular, the cognitive status associated with different kinds of dropped arguments. Regarding (a), if the analysis provided by the customization system isn't quite working, post to Canvas and we'll discuss how to fix it with tdl editing.
Regarding (b), you need to do the following:
Note that the Matrix currently assumings that dropped subjects are always [COG-ST in-foc]. This may not be true, especially in various impersonal constructions. If it's not true for your language, please let me know.
This part requires posting to Canvas!
Run your testsuite and examine the results to see if any sentences have >1 analysis. Use the Parse | Compare functionality to determine the sources of ambiguity, and try to decide whether any of the extra parses are (likely) warranted, or if they are just silly and should be ruled out. For those that should be ruled out, post to Canvas for ideas on how to go about doing so.
In order to get a sense of the coverage of our grammars over naturally occurring text, we are going to collect small test corpora. Minimally, these should consist of 10-20 sentences from running text. They could be larger; however, that is not recommended unless:
Note: 1,000 sentences is the maximum practical size for any single [incr tsdb()] skeleton. You could of course split your test corpus over multiple skeletons, but I'd be surprised if anyone got close to 1,000 sentences!
Note also that our grammars won't cover anything without lexicon. If you have access to a digitized lexical resource that you can import lexical items from, you can address this to a certain extent. Otherwise, you'll want to limit your test corpus to a size that you are willing to hand-enter vocabulary for. (If you have access to a Toolbox lexicon for your language, contact me about importing via the customization system.)
For Lab 5, your task is to locate your test corpus (10-20 sentences will be sufficient, more only if you want and you have access to the resources described above) and format it for [incr tsdb()]. If you have IGT to work with in the first place, it may be convenient to use the make_item script to create the test corpus skeleton. (Note that you want this to be separate from your regular test suite skeleton.) Otherwise, you can use [incr tsdb()]'s own import tool (File | Import | Test items) which expects a plain text file with one item per line. The result of that command is a testsuite profile from which you'll need to copy the item (and relations) file to create a testsuite skeleton.
Check list:
For each of the following phenomena, please include the following your write up:
Describe the process you went through to beat back ambiguity. What was the average ambiguity when you started, and what was it when you finished? What were the sources of ambiguity, and what constraints did you add to the tdl to remove them?
In addition, your write up should include a statement of the current coverage of your grammar over your test suite (using numbers you can get from Analyze | Coverage and Analyze | Overgeneration in [incr tsdb()]) and a comparison between your baseline test suite run and your final one for this lab (see Compare | Competence).
Finally please briefly describe your test corpus, including: where you collected it, how many sentences it contains, and what format (transliterated, etc) it is in.
svn export yourgrammar iso-lab5For git, please do the equivalent.
tar czf iso-lab5.tgz iso-lab5