As usual, check the write up instructions first.
There are several places in this lab
where I ask you to contact me if your grammar requires information
not in these instructions. Please read through this lab by class on
Tuesday, preferably earlier, so we can start that conversation in a timely fashion.
Requirements for this assignment
Before making any changes to your grammar for this lab, run a baseline test suite instance. If you decide to add items to your test suite for the material covered here, consider doing so before modifying your grammar so that your baseline can include those examples. (Alternatively, if you add examples in the course of working on your grammar and want to make the snapshot later, you can do so using the grammar you turned in for Lab 5.)
The semantics for declarative and interrogative clauses will be the same except for the value of the feature SF (sentential force) on the event index of the main predicate.
The customization script may have provided the right kind of syntax and semantics for matrix yes-no questions already. Try parsing an example from your test suite. If it parses, examine the MRS. Is the value of SF on the INDEX of the clause ques? (Or in the case of intonation questions only, do you get prop-or-ques?)
If your yes-no question doesn't parse, or if it does but not with the right semantics, contact me, and we will work out what needs to be done.
Some languages mark questions with an element (often a clitic) that goes right after the element that is the focus of the question and sometimes further requires that element to be the first thing in the sentence.
The general idea is that the question clitics are modifiers that attach to the right of the word they modify, and insist that that word be the initial thing in the sentence. The first step, therefore, is to add the feature which will check the position in the sentence. It turns out that this is rather involved, but the following worked for Russian and a handful of other languages.
canonical-synsem :+ [ L-PERIPH bool ].
(I'm leaving open for now the possibility that we might want a mirror-feature R-PERIPH.)
basic-binary-phrase :+ [ SYNSEM.L-PERIPH #periph, ARGS < [ SYNSEM.L-PERIPH #periph ], [SYNSEM.L-PERIPH -] > ].
basic-head-mod-phrase-simple :+
[ HEAD-DTR.SYNSEM.L-PERIPH #periph,
NON-HEAD-DTR.SYNSEM.LOCAL.CAT.HEAD.MOD < [ L-PERIPH #periph ] > ].
same-periph-unary-phrase := unary-phrase & [ SYNSEM.L-PERIPH #periph, ARGS < [ SYNSEM.L-PERIPH #periph ] > ].
question-clitic-lex := no-hcons-lex-item &
[ SYNSEM.LOCAL [ CAT [ VAL [ SPR < >, COMPS < >, SUBJ < >, SPEC < >],
HEAD adv &
[ MOD < [ LIGHT +,
LOCAL intersective-mod,
L-PERIPH + ] > ]],
CONT.RELS <! !> ]].
arda_gr := generator_rule &
[ CONTEXT.RELS <! [ ARG0.SF ques ] !>,
FLAGS.TRIGGER "LEX-ID-HERE" ].
s-coord-phrase :+
[ SYNSEM.LOCAL.CAT.MC bool,
LCOORD-DTR.SYNSEM.LOCAL.CAT.MC bool,
RCOORD-DTR.SYNSEM.LOCAL.CAT.MC bool ].
s-bottom-coord-phrase :+
[ SYNSEM.LOCAL.CAT.MC bool,
NONCONJ-DTR.SYNSEM.LOCAL.CAT.MC bool ].
That should be enough to get the question clitic appearing in the right place. When you've done this much, stop and check. And of course post to Canvas if it's not working :). While you're testing, make sure that the LIGHT value of the constituent containing the quesiton clitic and the thing to its left is - ... otherwise, this will spin on generation. If it's not [ LIGHT - ], then post to Canvas and we'll figure out how to make sure that it is.
The goal of the second part of the analysis is to correlate question semantics ([SF ques]) with the presence of a clitic in the clause. For Russian, at least, we need to allow the clitics to appear in embedded as well as matrix clauses, with the clause bearing the clitic being the one that's expressing a question.
The central idea here is for the question clitics to register their presence in a non-local feature, which is accumulated from both daughters. I wanted to use the feature QUE for this, but it seems that matrix.tdl includes some English-specific constraints regarding QUE in head-modifier constructions. For now, we'll work around by adding a new non-local feature YNQ. There will be a non-branching rule (int-cl) which empties the YNQ list and returns L-PERIPH to underspecified, so that the clitics can appear in embedded clauses. Because we need to make sure that the int-cl rule applies at the top of the clause, we'll be (ab)using MC a bit: The rest of the rules will say [MC na] (not-applicable) on the mother, and insist on [MC na] on the head-daughter. The int-cl rule (and a parallel decl-cl rule that this requires) will say [MC bool], compatible with the root condition ([MC +]) and the complement position of clause embedding verbs ([MC -]).
This entails the following changes:
non-local :+ [ YNQ 0-1-dlist ].
basic-binary-phrase :+
[ SYNSEM.NON-LOCAL.YNQ [ LIST #list,
LAST #last ],
ARGS < [ SYNSEM.NON-LOCAL.YNQ [ LIST #list,
LAST #middle ]],
[ SYNSEM.NON-LOCAL.YNQ [ LIST #middle,
LAST #last ]] > ].
same-ynq-unary-phrase := unary-phrase &
[ SYNSEM.NON-LOCAL.YNQ #ynq,
ARGS < [ SYNSEM.NON-LOCAL.YNQ #ynq ] > ].
question-clitic-lex := no-hcons-lex-item &
[ SYNSEM [ LOCAL [ CAT [ VAL [ SPR < >, COMPS < >, SUBJ < >, SPEC < >],
HEAD adv &
[ MOD < [ LIGHT +,
L-PERIPH + ] > ]],
CONT.RELS <! !> ],
NON-LOCAL.YNQ <! *top* !> ]].
non-ynq-word := word-or-lexrule & [ SYNSEM.NON-LOCAL.YNQ 0-dlist ]. basic-zero-arg :+ non-ynq-word. basic-one-arg :+ non-ynq-word. basic-two-arg :+ non-ynq-word. basic-three-arg :+ non-ynq-word. intersective-mod-lex :+ non-ynq-word.
root := phrase &
[ SYNSEM [ LOCAL [ COORD -,
CAT [ VAL [ SUBJ < >,
COMPS < > ],
MC +,
HEAD +vc &
[ FORM finite ] ] ],
NON-LOCAL.YNQ 0-dlist ] ].
int-cl := head-only & interrogative-clause &
[ SYNSEM [ LOCAL.CAT [ VAL #val,
MC bool ],
NON-LOCAL.YNQ <! !> ],
HEAD-DTR.SYNSEM [ LOCAL.CAT [ MC na,
VAL #val ],
NON-LOCAL.YNQ <! *top* !> ]].
decl-cl := head-only & declarative-clause & same-ynq-unary-phrase &
[ SYNSEM.LOCAL.CAT [ VAL #val,
MC bool ],
HEAD-DTR.SYNSEM [ LOCAL.CAT [ MC na,
VAL #val ],
NON-LOCAL.YNQ 0-dlist ]].
mc-na-headed-phrase := headed-phrase &
[ SYNSEM.LOCAL.CAT.MC na,
HEAD-DTR.SYNSEM.LOCAL.CAT.MC na ].
binary-headed-phrase :+ mc-na-headed-phrase.
We will be using clausal complements as our example of embedded clauses. To do so, we need to create clause-embedding verbs. First, if you haven't already, find examples of verbs that can embed propositions and verbs that can embed questions. If you also find verbs that are happy to embed either, we can make use of them. For inspiration, you can look here or here.
Below are notes written when the customization system didn't get have a library for clausal complements. Much of this should correspond to tdl already in your grammars, though likely not the parts that deal with interrogative clausal complements.
If your matrix and embedded clauses look the same, you should be able to test this immediately. Otherwise, you'll have to wait until you've implemented the syntax for your embedded clauses. (Though to test the semantics, you could say that the COMPS value of the verb is an S, and try an example where a matrix clause appears in that complement position.)
Some languages mark embedded clauses (declaractive, interrogative or both) with complementizers (e.g., that and whether in English). To implement this, you'll need to do the following. (If your language also marks matrix questions with a question particle, you have some of the following in your grammar already.)
Test your embedded clauses. Do they parse as expected? Can you still generate?
Note: You'll need to add trigger rules for any complementizers, since they do not contribute any eps on their RELS list. Here is an example for a complementizer that goes with embedded declaratives: (And if you have other semantically empty things, contact me about designing trigger rules for them, too.)
comp_gtr := generator_rule &
[ CONTEXT [ RELS <! [ ARG2 #h & handle ],
[ ARG0 #e & event ] !> ],
FLAGS [ EQUAL < #e, #h >,
TRIGGER "name_of_comp_entry" ]].
Other possible syntactic differences between main and subordinate clauses include:
Consult with me to work out an analysis for whatever your language is doing in this case.
If your matrix and embedded clauses have different syntactic properties (e.g., presence v. absence of complementizers), you'll need to constrain things so that the embedded clause syntax only appears in embedded clauses and vice versa for matrix clause syntax. There are three resources for doing so:
If the difference is strictly S v. CP, you don't need the feature MC. Otherwise, you probably will need all three: The root condition will require [MC +], the embedding verb will require [MC -], and the constructions/lexical rules/etc which create the embedded and matrix clauses themselves should set appropriate values for MC.
Be sure your test suite contains negative examples illustrating
matrix clause syntax in embedded clauses and vice versa.
Check your MRSs
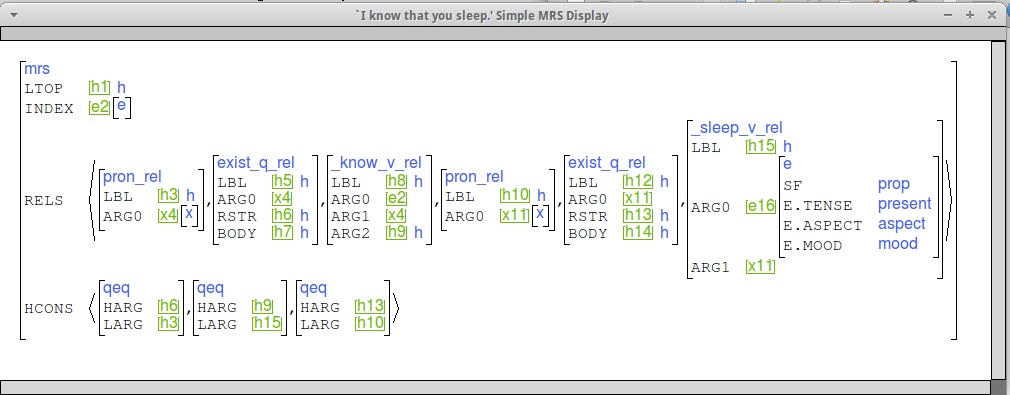
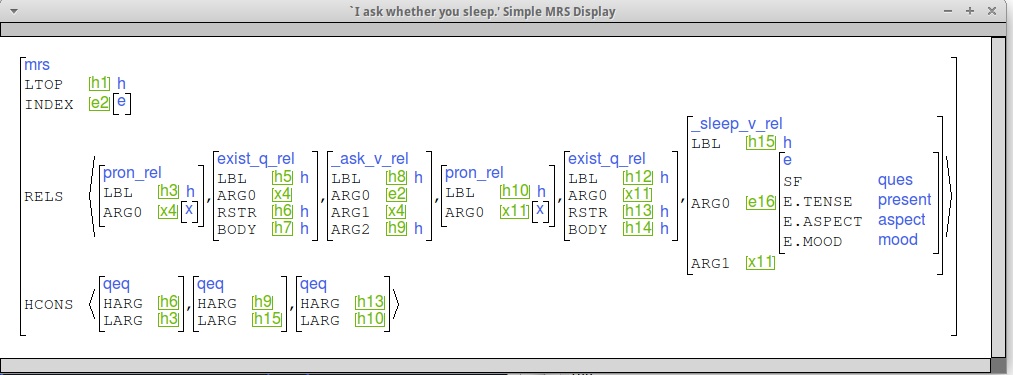
Here are some examples to give you an idea of what we're looking for. (This is the "indexed MRS" view.)
Note the qeq linking the ARG2 position
of _know_v_rel (h9) to the LBL of _sleep_v_rel (h15),
and the SF value of e16 (PROP).
Note the qeq linking the ARG2 position
of _ask_v_rel (h9) to the LBL of _sleep_v_rel (h15),
and the SF value of e16 (QUES).
In constructing your testsuite for this phenomenon in a previous lab, you were asked to find the following:
In the following, I'll share the tdl I've developed in a small English grammar, for two possibilities:
Your goal for this part of the lab is to use this as a jumping-off point to handle wh questions as they manifest in your language. Of course, I expect languages to differ in the details, so please start early and post to Canvas so we can work it out together.
Type and entry definitions for my tdl pronouns (used in both versions):
wh-pronoun-noun-lex := norm-hook-lex-item & basic-icons-lex-item &
[ SYNSEM [ LOCAL [ CAT [ HEAD noun,
VAL [ SPR < >,
SUBJ < >,
COMPS < >,
SPEC < > ] ],
CONT [ HOOK.INDEX.PNG.PER 3rd,
RELS <! [ LBL #larg,
ARG0 #ind & ref-ind ],
[ PRED "wh_q_rel",
ARG0 #ind,
RSTR #harg ] !>,
HCONS <! [ HARG #harg,
LARG #larg ] !> ] ],
NON-LOCAL.QUE <! #ind !> ] ].
what := wh-pronoun-noun-lex &
[ STEM < "what" >,
SYNSEM.LKEYS.KEYREL.PRED "_thing_n_rel" ].
who := wh-pronoun-noun-lex &
[ STEM < "who" >,
SYNSEM.LKEYS.KEYREL.PRED "_person_n_rel" ].
In order to make sure the diff-list appends for the non-local features don't leak (leaving you with underspecified QUE or SLASH), there may be a few ancillary changes required. For example:
basic-head-filler-phrase :+
[ ARGS < [ SYNSEM.LOCAL.COORD - ], [ SYNSEM.LOCAL.COORD - ] > ].
wh-ques-phrase := basic-head-filler-phrase & interrogative-clause &
head-final &
[ SYNSEM.LOCAL.CAT [ MC bool,
VAL #val,
HEAD verb & [ FORM finite ] ],
HEAD-DTR.SYNSEM.LOCAL.CAT [ MC na,
VAL #val & [ SUBJ < >,
COMPS < > ] ],
NON-HEAD-DTR.SYNSEM.NON-LOCAL.QUE <! ref-ind !> ].
extracted-comp-phrase := basic-extracted-comp-phrase &
[ SYNSEM.LOCAL.CAT.HEAD verb,
HEAD-DTR.SYNSEM.LOCAL.CAT.VAL.SUBJ cons ].
extracted-subj-phrase := basic-extracted-subj-phrase &
[ SYNSEM.LOCAL.CAT.HEAD verb,
HEAD-DTR.SYNSEM.LOCAL.CAT.VAL.COMPS < > ].
Note that the constraints on SUBJ and COMPS in the two types just above are somewhat specific to English --- depending on the word order facts of your language, you may need to constrain them differently.
Note also that all the phrase structure rules require instances in rules.tdl. For example:
wh-ques := wh-ques-phrase.
Note that you do NOT want to create an instance of basic-head-filler-phrase directly. basic-head-filler-phrase is a supertype of wh-ques-phrase.
Note that all the phrase structure rules require instances in rules.tdl
wh-int-cl := clause & head-compositional & head-only &
[ SYNSEM [ LOCAL.CAT [ VAL #val,
MC bool ],
NON-LOCAL non-local-none ],
C-CONT [ RELS <! !>,
HCONS <! !>,
HOOK.INDEX.SF ques ],
HEAD-DTR.SYNSEM [ LOCAL.CAT [ HEAD verb & [ FORM finite ],
VAL #val &
[ SUBJ < >,
COMPS < > ] ],
NON-LOCAL [ SLASH <! !>,
REL <! !>,
QUE <! ref-ind !> ] ] ].
The general head-subj type assumes that QUE is empty, which won't fly in this case, so we need to redefine it. In the pseudo-English grammar, I did it this way:
eng-subj-head-phrase := head-valence-phrase & head-compositional &
basic-binary-headed-phrase &
[ SYNSEM phr-synsem &
[ LOCAL.CAT [ POSTHEAD +,
HC-LIGHT -,
VAL [ SUBJ < >,
COMPS #comps,
SPR #spr ] ] ],
C-CONT [ HOOK.INDEX.SF prop-or-ques,
RELS <! !>,
HCONS <! !>,
ICONS <! !> ],
HEAD-DTR.SYNSEM.LOCAL.CAT.VAL [ SUBJ < #synsem >,
COMPS #comps,
SPR #spr ],
NON-HEAD-DTR.SYNSEM #synsem & canonical-synsem &
[ LOCAL [ CAT [ VAL [ SUBJ olist,
COMPS olist,
SPR olist ] ] ],
NON-LOCAL [ SLASH 0-dlist & [ LIST < > ],
REL 0-dlist ] ]].
And then used this type in place of decl-subj-head-phrase in my definition of subj-head-phrase:
subj-head-phrase := eng-head-subj-phrase & head-final & [ HEAD-DTR.SYNSEM.LOCAL.CAT.VAL.COMPS < > ].
If your language has head-opt-subj, this will
need to be rewritten similarly.
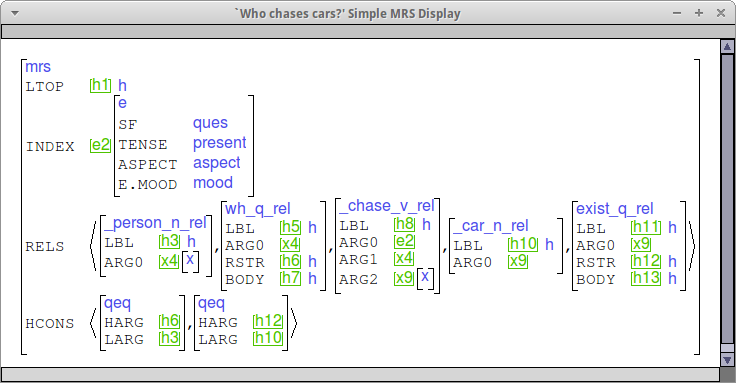
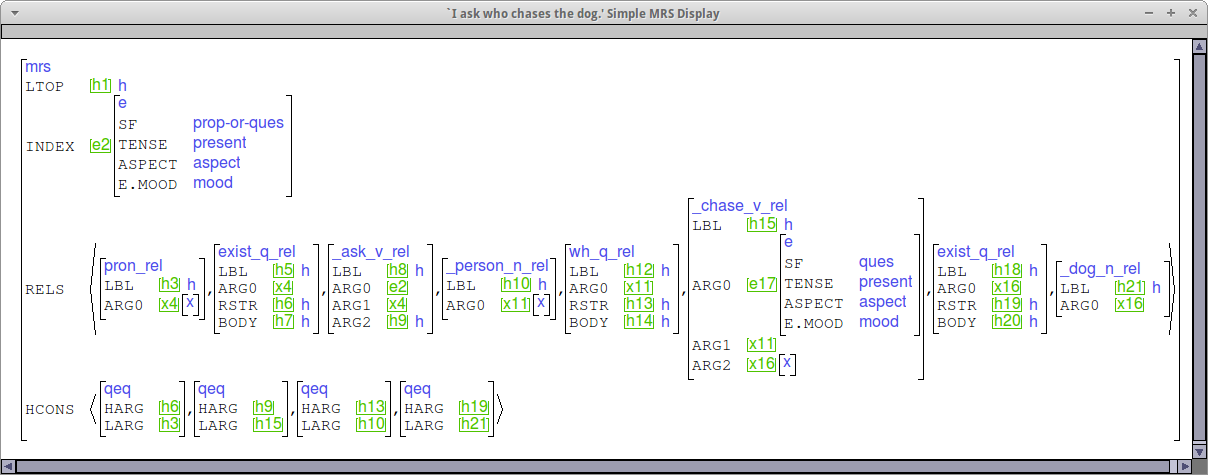
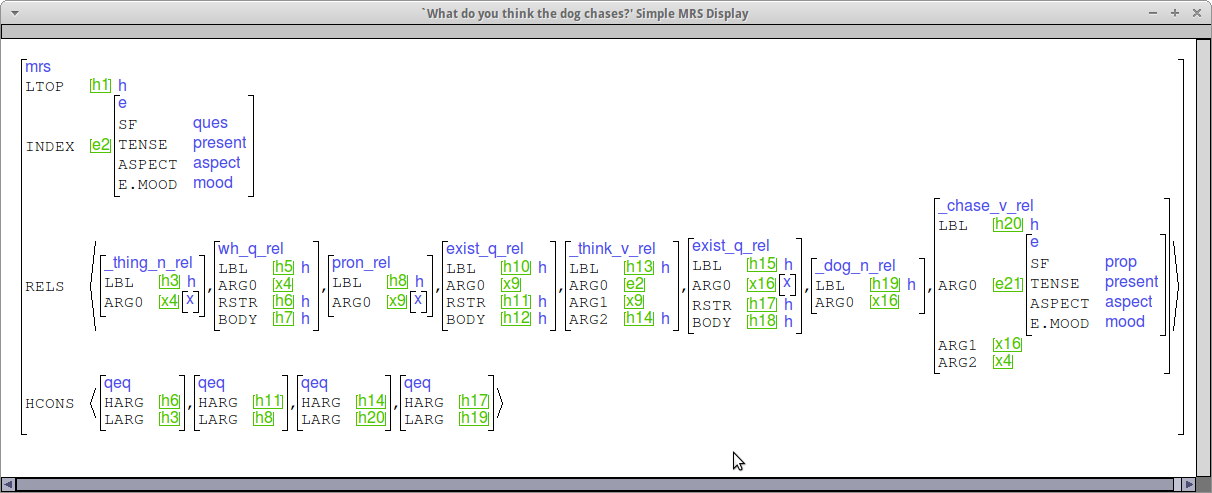
Check your MRSs
Below are some sample MRSs for wh questions, considering both subject and complement questions as well as matrix and embedded questions. Please use these as a point of comparison when you check your MRSs.
The goal of this section is to parse one more sentence from your test corpus than you are before starting this section. In most cases, that will mean parsing one sentence total. In your write up, you should document what you had to add to get the sentence working. Note that it is possible to get full credit here even if the sentence ultimately doesn't parse by documenting what you worked on and what you you still have to get working.
This is a very open-ended part of the lab (even more so than usual), which means: A) you should get started early and post to Canvas so I can assist in developing analyses of whatever additional phenomena you run accross and B) you'll have to restrain yourselves; the goal isn't to parse the whole test corpus this week ;-). In fact, I won't have time to support the extension of the grammars by more than one sentence each, so please *stop* after one sentence.
For each of the following phenomena, please include the following your write up:
In addition, your write up should include a statement of the current coverage of your grammar over your test suite (using numbers you can get from Analyze | Coverage and Analyze | Overgeneration in [incr tsdb()]) and a comparison between your baseline test suite run and your final one for this lab (see Compare | Competence).
svn export yourgrammar iso-lab6For git, please do the equivalent.
tar czf iso-lab6.tgz iso-lab6