CSS343
Author Name
Student ID
Revised Specification for
Program 2
Problem Statement
The goal of this program is to compress the memory
space taken up by a document by using the Huffman encoding method. The process is roughly divided into the
following phases:
1) Collecting the statistical data about a textual
document in the input file:
The program must open the input file and read the
textual document contained in the file a character at a time, storing the
character, if it has not been already
stored, in a binary search tree instance.
Each tree node must store both a character symbol and the number of its
occurrences for the document. For
example, if a character is stored for the first time, the number of its
occurrences is 1. If the character has
been already stored in the binary tree, and the same character is encountered
again, the program must update the number of its occurrences by incrementing it
by 1.
The binary search tree mentioned above must be
ordered by input characters read from the document so that updating the
statistical data about each character is efficient it allows the program to
find the tree node containing the character by
utilizing the binary search method.
2) Initializing the HuffmanTree class instances with
the statistical data stored in the binary search tree:
A HuffmanTree class instance is initially one-node
binary tree. Each HuffmanTree class
instance is initialized to store a character and the number of its
occurrences. An initialized HuffmanTree
class instance must be inserted into a heap we call it a Forest class
instance in a manner ordered by the number of character occurrences.
3) Building one HuffmanTree class instance that
integrates all other HuffmanTree instances in the forest:
After initialization, the Forest class instance
becomes populated with one-node HuffmanTrees.
These HuffmanTrees are sorted according to the number of character
occurrences.
Combine the two HuffmanTrees with the lowest number
as the left and right subtrees of a new HuffmanTree. Assign the sum of the two numbers as the number of occurrences
for the root data of the new tree, but leave its character symbol empty.
Delete the two old HuffmanTrees from our Forest.
Insert the newly combined tree into the proper
position of our Forest so that our Forest retains the heap properties.
Repeat the above steps until there is only one
HuffmanTree instance left for our Forest.
Our Forest will eventually contain one HuffmanTree
instance in which all relevant characters are located at its leaves.
4) Creating a table that contains all characters
with their associated Huffman codes:
In order to create the table, our Forest traverses
its HuffmanTree until it reaches at a leaf.
Meanwhile, it records either 0 or 1, depending on the direction of the
tree it is traversing. The resulting
code is stored in our Table class instance, along with its associated ASCII
character symbol. This process is
repeated until all of the leaves are traversed.
The table elements are sorted according to the ASCII
value of character symbols.
5) Browsing the input file for the second time and
converting each character into its associated Huffman code using the table
mentioned above as a reference:
Read a character at a time. Find the character in the table. If found, retrieve its associated Huffman
code. Convert the string representation
of the code into its binary equivalent.
6) Output the converted Huffman codes into a binary
file a byte at a time.
7) Repeat the processes 5 and 6 until the end of
file is encountered. If the encoding of
the last character in the input file comes short of a byte, pack 0s for the
remaining bits so that the last byte can be written to the output file.
Input Data
Two command lines that represent the input file name
and the output file name. The command
line arguments are passed into the programs main function. The input file is supposed to contain a
document in the text format.
Output Data
Binary bits that represent the Huffman codes for all
characters found in the input file. The
program writes them into the designated output file. The output file must be in binary mode.
Error Handling
1) The program must check if the input file actually
exists. If not, it must give an error
message to that effect and exit the program.
2) The program must check if the output file
actually exists. If not, it must create
one with the designated file name. If
it encounters a problem with opening the output file, then it must give an
error message to that effect and exit the program.
3) The program must check the status of ifstream
before reading the next character. It
must clear the ifstream whenever the EOF status is suspected.
Test Plan
|
Input |
Expected Output |
Rationale |
|
An
empty file |
None. The
program does nothing in this case. |
To
see if the program handles an empty file. |
|
A
file containing a single character of a |
00000000 The
program generates the Huffman code of 0 for a single input and packs 0s to
fill the remaining 7 bits. |
To
see if the program handles a file containing a single character. |
|
A
file containing a string of aa |
00000000 The
program generates the Huffman code of 0 for the character a. The program therefore converts the string
aa into the Huffman code of 00 and packs 0s to fill the remaining 6 bits. |
To
see if the program handles a file containing a couple of the same character. |
|
A
file containing a string of a |
01000000 The
program generates the Huffman code of 0 for the first character a space,
and the Huffman code of 1 for the second character a. The program therefore converts the string
a into the Huffman code of 01 and packs 0s to fill the remaining 6 bits. |
To
see if the program handles a file containing two different characters. |
|
A
file containing a string of b ./cdeeVgaboa ax*** 7 |
11111110
11111100 10011101
10110001 01010100
10110111 10011100
10010000 00110111
00000101 10110110
01011010 |
To
see if the program handles a file containing a string of various characters,
such as letter characters, non-letter characters, spaces and a newline
character. |
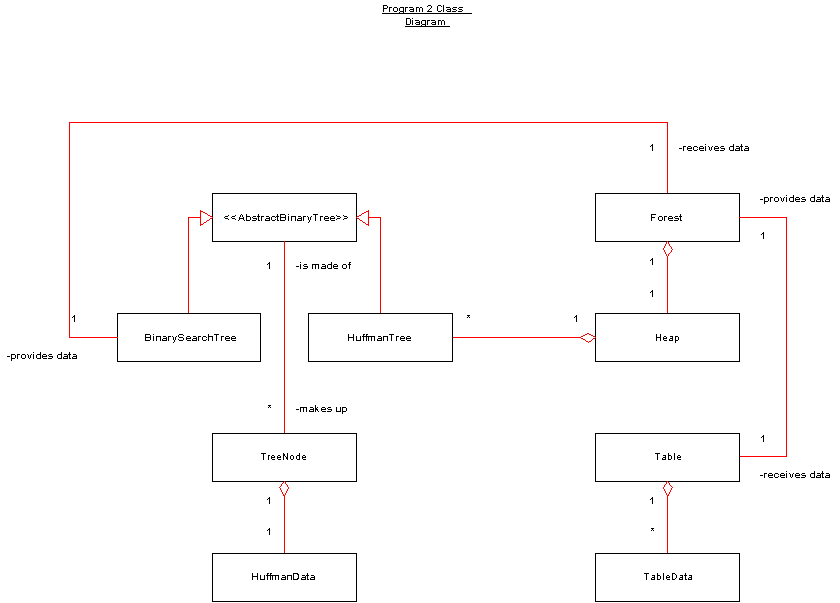
Class Definitions
Class Relationships