Introduction to Geographic Information Systems in Forest Resources
| Introduction to Geographic Information Systems in Forest Resources |
|
|||||||||||||||
|
|||||||||||||||
You should now know the fundamentals of GIS, as applied in ArcGIS.
Thorough knowledge of these topics are necessary before undertaking any analytical tasks. In this section basic vector analysis will be discussed.
One of the most basic analytical tasks in a GIS is locating features in one layer based on the location of other features in the same layer or in another layer. This type of relationship is based on the spatial properties of the layers, including the spatial extent and location of features within layers, as well as the feature type of the layers.
Here are some examples of analytical questions which can be answered with these methods:
Analyzing spatial relationships
Analyzing spatial relationships
Many of the reasons GISs were developed were to answer conceptually simple, but technically difficult spatial questions. These questions include relationships of adjacency, proximity, intersection, and containment of features among different layers. ArcGIS 's basic spatial analysis functionality includes methods to deal with these analytical tasks.
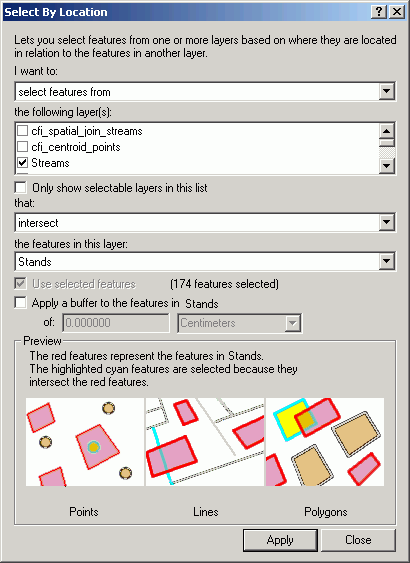
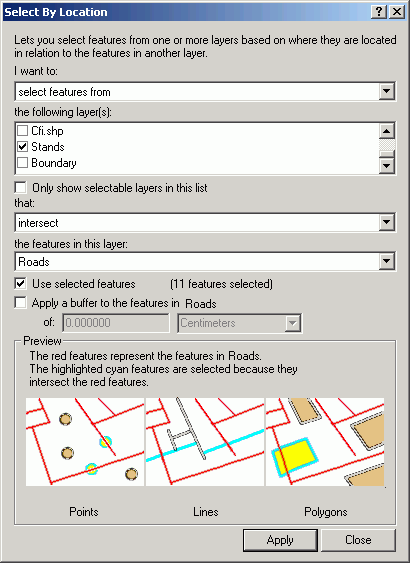
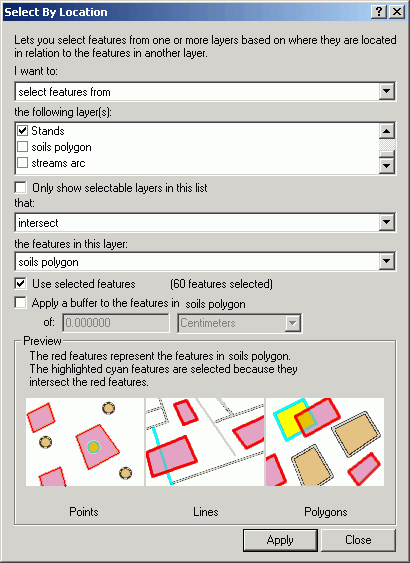
Select By Location is a very versatile tool used to select features in one or more layers based on the spatial (locational) relationship to another layer. Features in one or more layers that share the same space, or are near to, selected features in another layer, can be selected, displayed, and analyzed. The layers used in select by location are known as the target layer(s) and the selector layer. The selector layer contains features that are known or selected, and the target layer(s) contain features that we are curious about.
Based on the feature type of the target and selector layers, several possible spatial relationships exist:
spatial
relationshippurpose target layer
feature typesselector layer
feature typesare completely within selects target layer features
that are completely within
selector layer featurespoint
line
polygonpolygon completely contain selects target layer features
that completely contain
selector layer featurespolygon point
line
polygonhave their center in selects target layer features
whose centers fall inside
selector layer featurespoint
line
polygonpolygon contain the center of selects target layer features
which contain the centers of
selector layer featurespolygon point
line
polygonintersect selects target layer features
that intersect
selector layer featurespoint
line
polygonline
polygonare within distance of selects target layer features
that are within a given distance of
selector layer featurespoint
line
polygonpoint
line
polygon
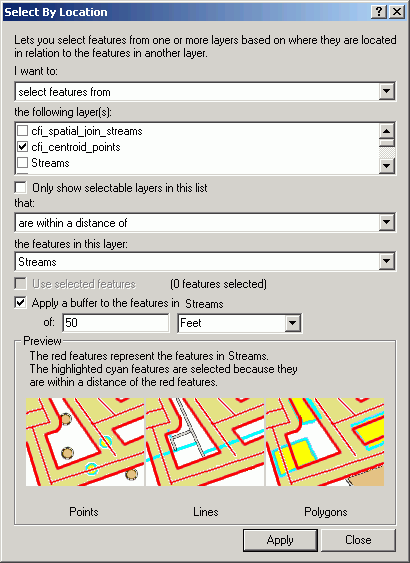
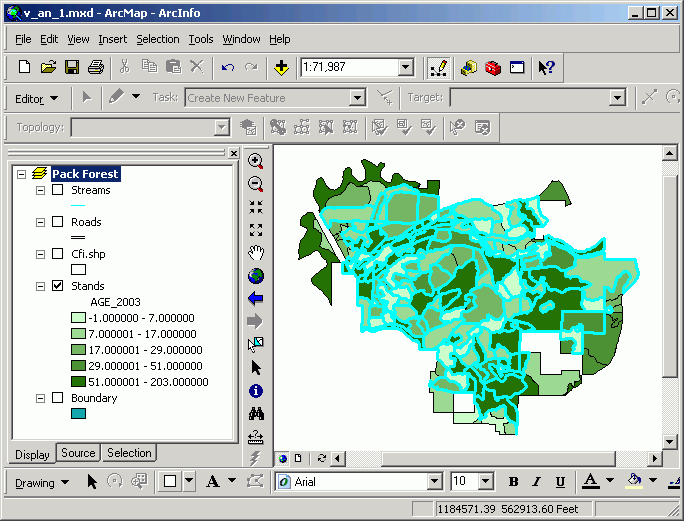
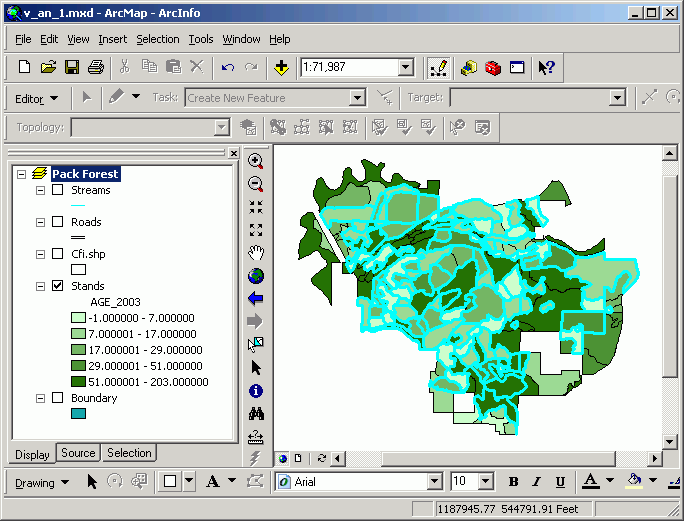
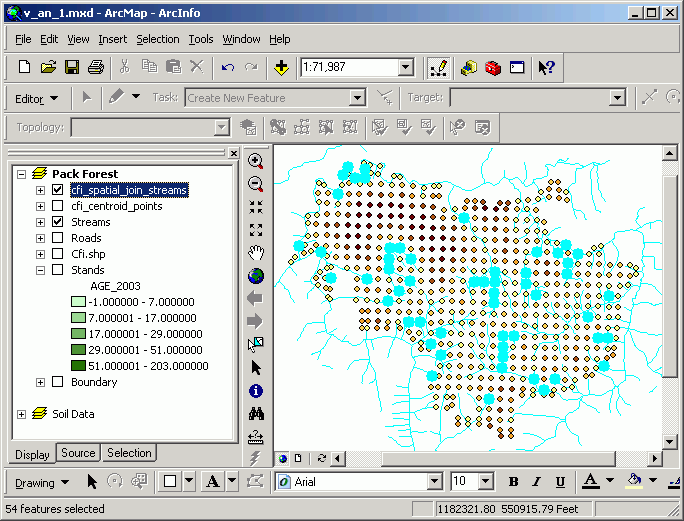
To select points near a line, the Select By Location method is used. The dialog is straightforward and reads like a natural language statement. Here, we are selecting features from a point layer (cfi_centroid_points) that are within 50 ft from a stream.
The resultant selection is displayed. The results of this kind of selection are just like what you get with a query statement, but rather than selecting based on attributes in the table, the selection is made on the spatial properties of the data objects.
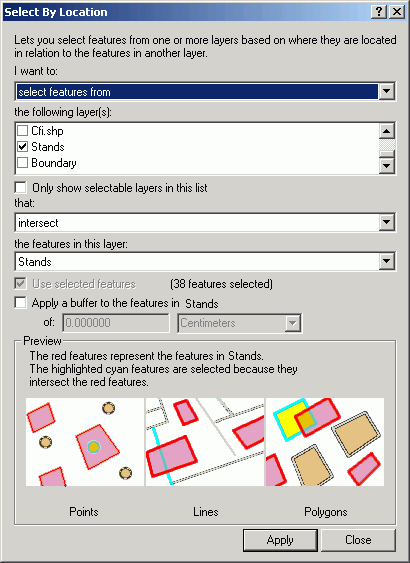
To select features that are adjacent to other features within the same layer, first make a selection on the layer. Here, stands that are 71-80 years old are selected:
Select By Location allows you to select features that are adjacent to the current selected set:
In many cases the selection is between different layers, but in this case the selection is on the same layer. The resultant selection shows the original selected set as well as those touching selected polygons:
Deselecting the originally selected stands results in a selection of only those that are adjacent to, but not including, stands of 71-80 years of age.
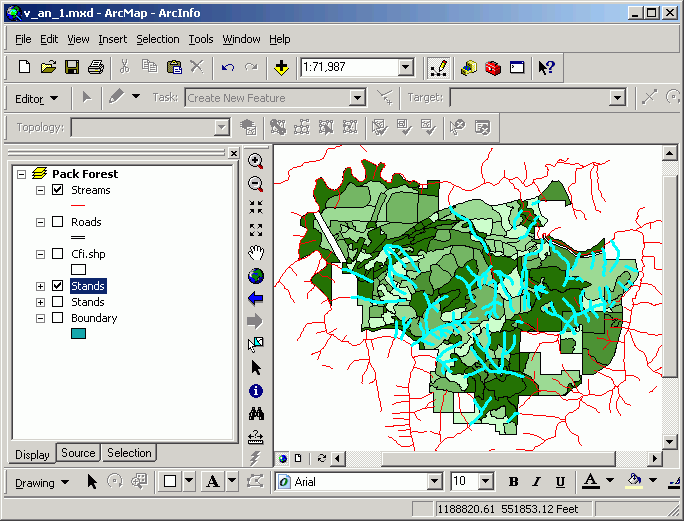
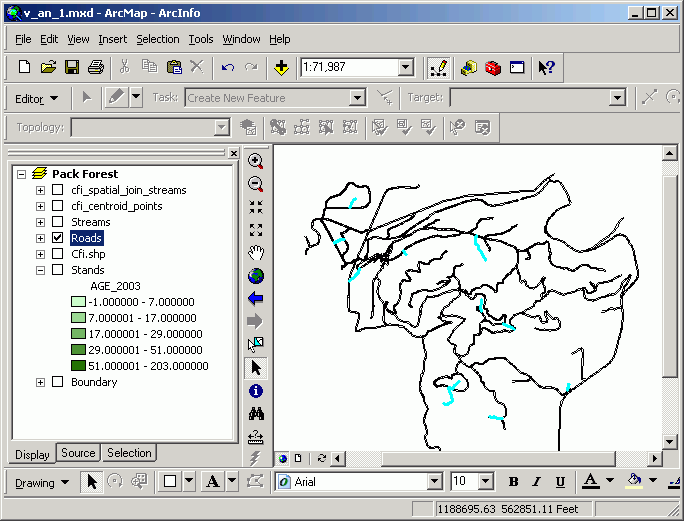
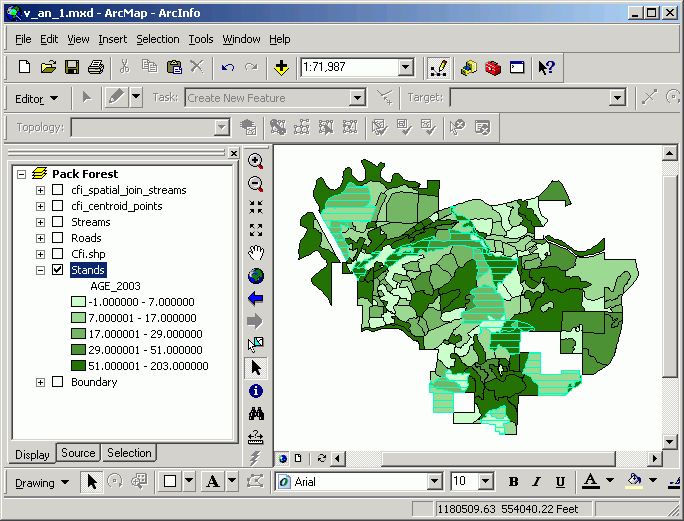
A common question for land and resource management is "What streams/roads/highways pass through a given set of stands/subdivisions/counties?" Line-on-polygon selection is used to select linear features that fall on top of selected polygonal features. To follow the above example through, we shall find the streams and roads that pass through the selected set of stands.
The Select By Location will select only those streams that intersect with the selected set of stands.
Which selects those streams and roads passing through the selected set of stands (the selection on stands is not displayed in the image below, in order to make the selected streams more visible).
Polygon-on-line selection is the reverse of the previous example. In the previous example, we have a selected set of polygons, and we are interested what linear features pass through these polygons. In this case, we are interested in the polygons that are on top of a selected set of linear features.
For example, a stream monitoring project may have identified tertiary roads as a source of sedimentation. We are interested in identifying the forest stands through which these road segments pass, in order to see if there is a relationship between forest land management practices and road sedimentation.
In this case, select roads of interest from the Roads (USE_CLASS = Tertiary)
and then select forest stands that intersect with the selected road segments:
The new selected set of stands are those through which the selected roads pass:
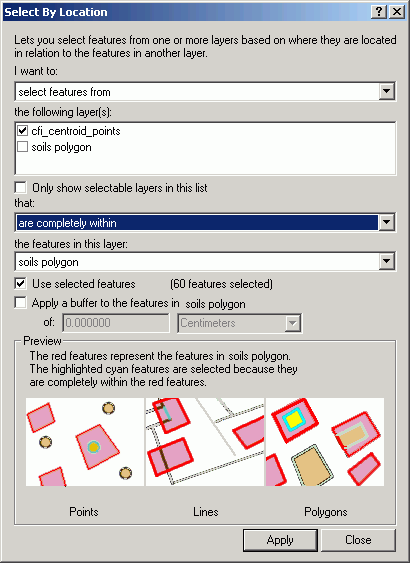
Point-in-polygon selection is used to identify point features from one layer which are located within selected polygons of another layer. The point layer is the target, while the polygon layer is the selector.
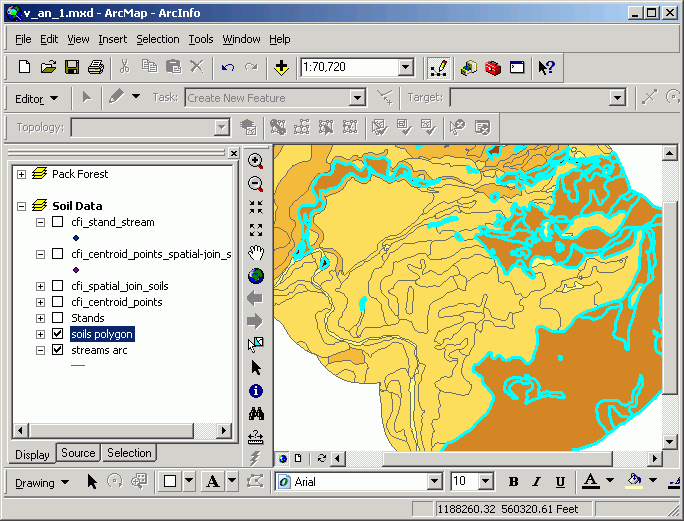
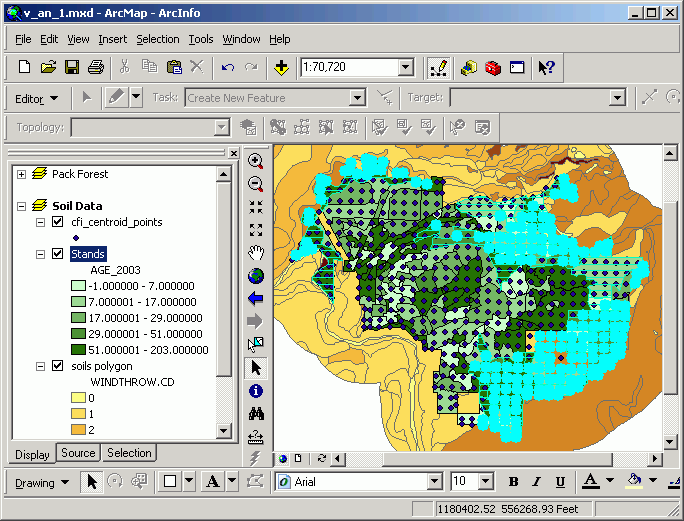
For this example, examine the Pack Forest continuous forest inventory (CFI). Is there a pattern between soils properties and the amount of standing timber?
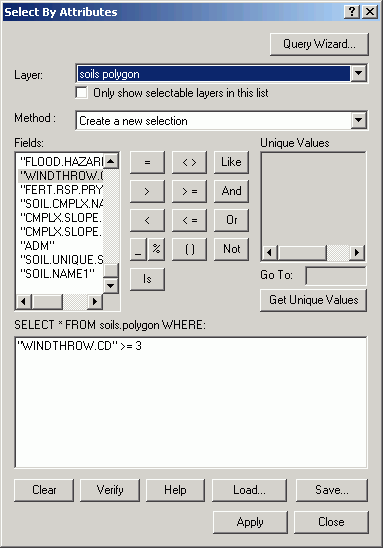
Here, soils that have a moderate to high windthrow potential are selected
This Select By Layer query selects CFI plots centers within these soils polygons:
The selected CFI plot centers are selected.
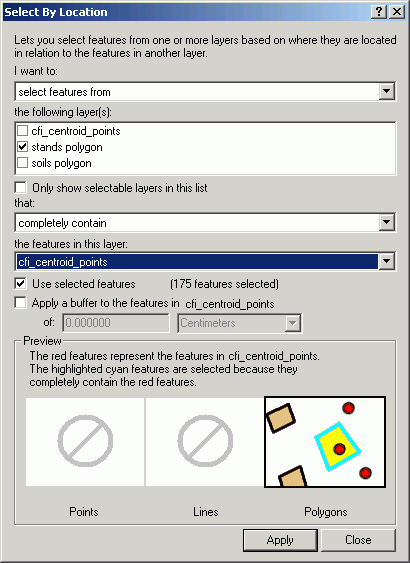
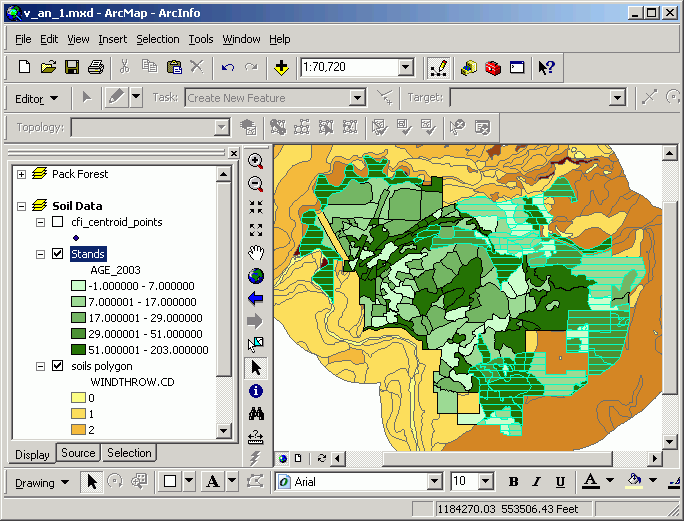
Polygon-on-point selections are the reverse of the previous case. Here, we are interested in the value of polygons which lie on top of selected point features. Polygon-on-point selection could be used to determine habitat preferences for bird nesting areas. Assuming we have a habitat polygon layer (land use, land cover, seral stage, vegetative species, etc.), we could select polygons that share the same space as nest sites.
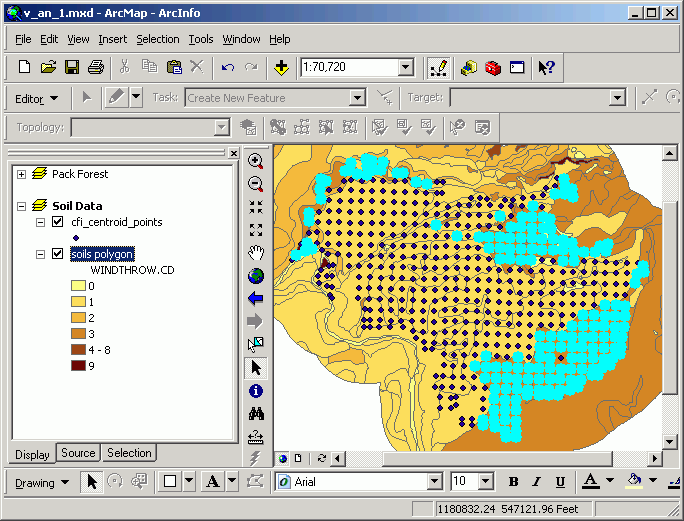
Continuing with the previous example, let's find the stands that contain inventory points that also have moderate to high windthrow potential. We select stands that completely contain the previously selected points:
Then stands sharing the same space are located.
Points turned off to display only the selected set of stands:
Polygon-on-polygon selection is the selection of the intersection of two selected sets of polygons from separate layers. An example would be the identification of forest stands that have been affected by a recent burn. This "intersection" does not select the spatial area in common between the two layers, but completely selects any polygons where there is any overlap. True intersection will come in the next module, Vector Analysis 2.
In the following example, we will identify stands which have at least part of their area in soils with moderate to high windthrow potential. First, select the Soils polygons containing moderate to highly susceptible soils:
Then make a selection of stands polygons which intersect with the selected set of soil polygons.
The map can be used for field reconnaissance to help determine what measures may need to be taken to minimize losses due to windthrow in these areas.
Spatial join
Spatial joins are a special case of tabular joins, but instead of joining tables based on a common attribute field, attribute tables are joined by the use of the shape field. Like other tabular joins, this appends a source table to a destination table, but the results are somewhat different. Spatial joins append the attributes of one layer to the attributes of another layer, based on the property of proximity or containment, rather than by typical primary-foreign key relates.
Two types of spatial relationships are used to compare the locations of the features in the joined layers: nearest and inside. Like the other types of spatial analysis in ArcGIS, the type of spatial join is also dependent on the layer feature type. This matrix shows the relationships which are possible between source and destination attribute tables, based on the layer feature type:
source
layerpoint
line
polygon
destination
layerpoint
proximity
proximity
containment
line
proximity
part of
containment
polygon
N/A
N/A
containment
The destination layer is the layer we are interested in making a selection on. The source layer contains features that we want to use for defining the selection on the destination layer.
In the proximity relationship, the record for the feature in the source table that has the greatest proximity to the record for the feature in the destination table is appended to the record in the destination table.
In the containment relationship, the record for the polygon (source) completely containing the line or point (destination) is appended to the destination table's record.
The part of relationship applies only to line layers in which lines in one layer are subsets of lines in another layer.
A spatial merge creates a new layer in which multiple input features one common attribute value are merged into single features. The new features need not be adjacent. The new features, although possibly composed of many objects (points, lines, or polygons), are stored as one single feature with one single attribute record. When one individual object of the feature is selected, all objects of that feature are selected.
The relationship of containment is used when we want to know what polygons contain features from other layers.
Whenever the source layer feature type is polygon, the spatial relationship between it and the destination layer is containment. This is because a polygon in the source either will or will not contain another point, line, or polygon. If any destination layer features are completely contained within source layer polygons, then the source layer attributes are appended to the corresponding destination layer records. Where destination layer features are not completely contained within source layer polygons, the newly appended fields will appear with blank values.
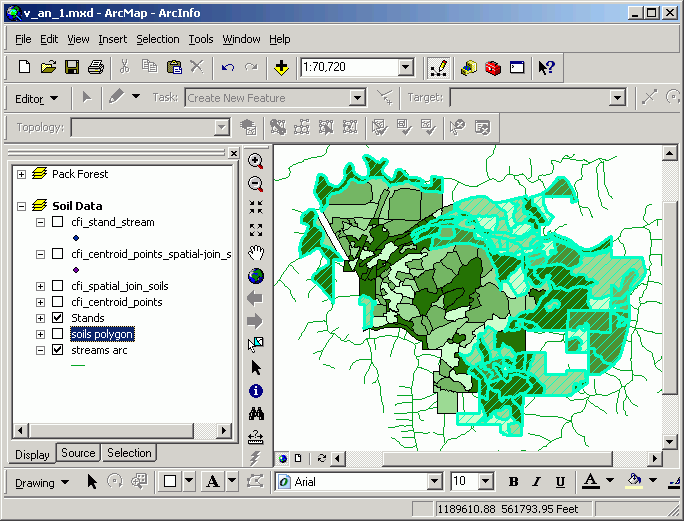
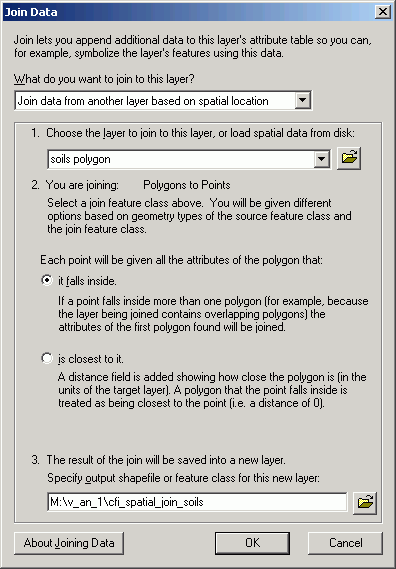
Performing spatial joins involves creating new data sets that will have their attribute structure altered based on the spatial relationship between the two layers. Here is the setup of a join between soils points and CFI plots:
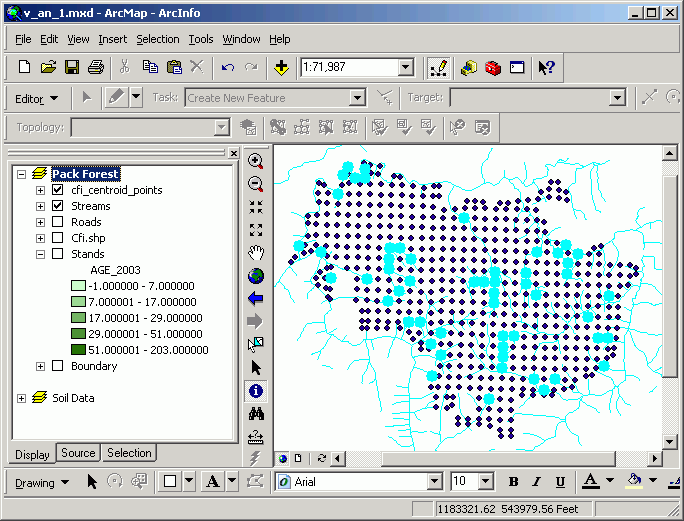
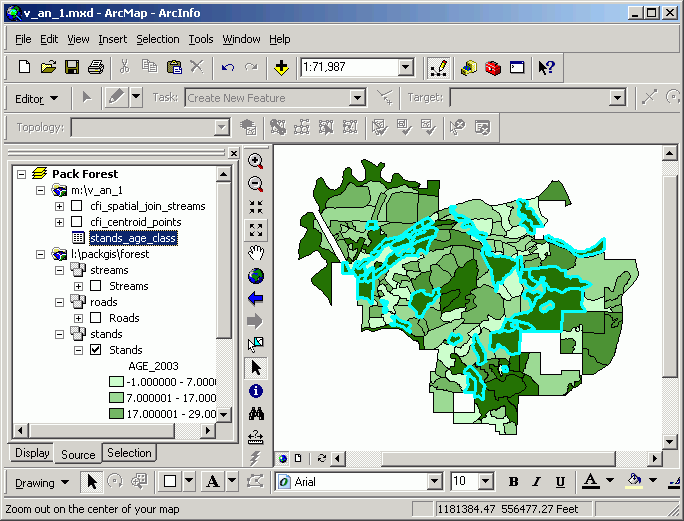
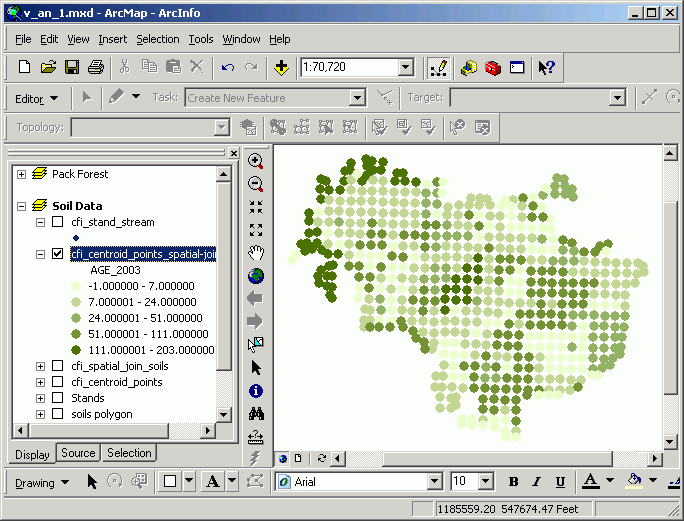
In the following image, a join has been performed between inventory plots and stands. As with all attribute tables, it is possible to change view properties based on an attribute value; here, CFI plots are mapped according to the age of the stand in which they lie. This may seem trivial, this map would be difficult to make without a GIS, because age is not an explicit attribute of the CFI plots. It is the spatial join that allows this type of analysis.
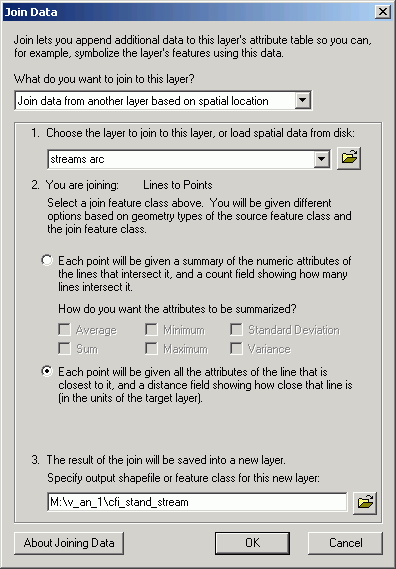
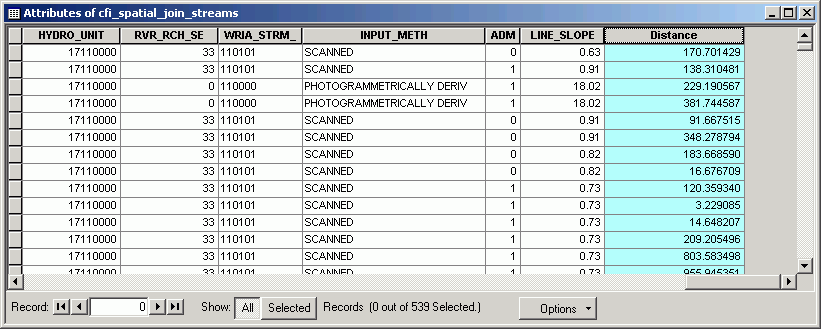
If the destination layer represents point or line data, it is possible to find the nearest point, line, or polygon in a source layer. In addition to the source table attributes being appended to the destination table, a field called distance is also added to the table, representing the distance between the source and destination features.
Here, we find and map the distance of CFI plots to existing streams by joining streams onto CFI plot points. Note that after the join, the field Distance appears.
The plots can be mapped according to their distance from existing streams. Here are those plot centers within 50 ft of a stream (selected by a query on the attributes, "Distance" < 50).
Because the inventory plots have measurements of the number and sizes of different tree species, it is possible to check whether species composition is different for inventory plots near streams. Quantification of riparian vegetation is an important topic with respect to shade requirements and coarse woody debris recruitment.
Return to top | Ahead to Help Topics
|
|||||||||||||||

|
The University of Washington Spatial Technology, GIS, and Remote Sensing Page is supported by the School of Forest Resources |
School of Forest Resources |